Creation
Creation is a type of RAIL stage which creates and models samples of photometric catalogs of galaxies, and modifies them to add noise and biases. Creation stages use creators to generate data, and degraders to add noise.
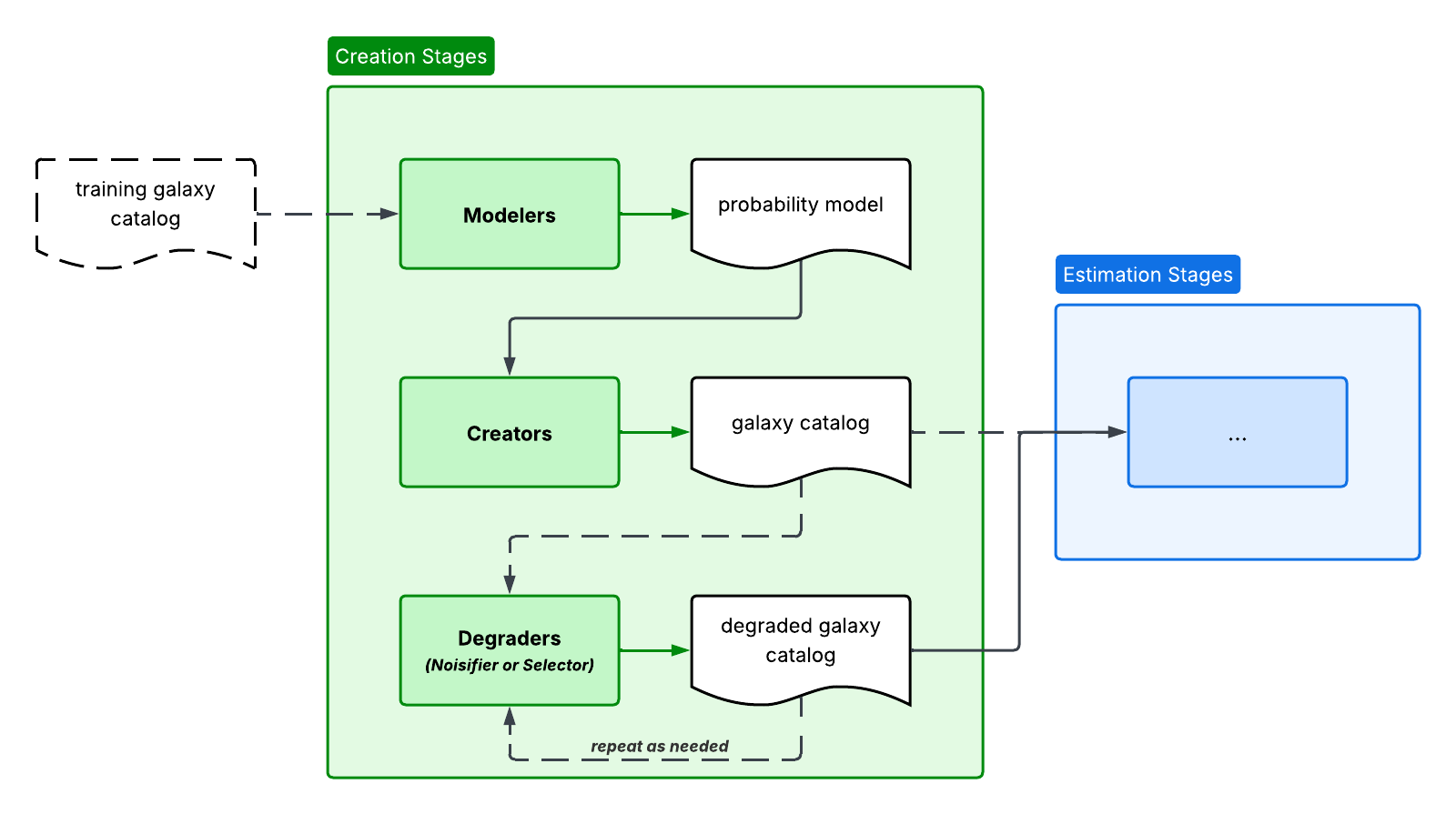
Creators
Mock DESC data are important for systematically testing the performance of various photo-\(z\) algorithms. One of the lessons learned from DC1 is that it is desirable for the mock data to include not only true redshifts and LSST photometry (i.e., fluxes in the six LSST bands) but also true posterior PDFs, \(p(z_t | \mathbf{p}_t)\), which are unavailable for spectroscopically confirmed data sets as well as traditional simulations. Furthermore, the mock photometry data should contain realistic noise, selection effects, and biases. This is critical for the training and validation of photo-\(z\) algorithms.
To address these needs, rail.creation enables us to create datasets
with true PDFs that allow PDF-to-PDF metrics computations and forward-modeling
of mock data for validating photo-z approaches under realistically complex
conditions. This is realized by two main types of stages within
rail.creation: (1) engines that forward-model photometric catalogs
and (2) degraders that modify such catalogs to introduce tunable physical
imperfections.
An engine is defined by a pair of stages that are subclasses of each of the
following superclasses: rail.creation.Modeler makes a model of the
\(p(z, \mathrm{photometry})\) joint probability space based on input parameters or
data, and rail.creation.Creator samples \((z, \mathrm{photometry})\)
from the forward model.
FSPS (Flexible Stellar Population Synthesis)
RAIL Package: https://github.com/LSSTDESC/rail_fsps
FSPS is a RAIL module that creates an interface to the Python bindings of
the popular stellar population synthesis (SPS) code FSPS (Flexible Stellar
Population Synthesis, Conroy et al. 2009, 2010). FSPS aims at generating
realistic galaxy spectral energy distributions (SEDs) by modelling all the
components that contribute to the light from a galaxy: stars, gas, dust and AGN.
FSPS is widely used both for stellar population inference (Johnson et al.
1) and for forward modelling of galaxy SEDs (e.g., Alsing et al. 2023,
Tortorelli et al. 2024).
FSPS provides substantial flexibility in terms of the prescription for
modelling each of the mentioned components. It also requires physical properties
of galaxies as input, such as star formation histories (SFHs), metallicities and
redshift, in order to generate their SEDs. We maintained this flexibility in the
interface we implemented in RAIL, allowing the user to change every possible
FSPS parameter. The code has been parallelized to make efficient use of the
multiprocessing capabilities of CPUs.
The interface is integrated in the RAIL workflow, requiring as input a catalog
of galaxy physical properties in the form of Hdf5Handle. These are galaxy
redshifts, stellar metallicities, velocity dispersions, gas metallicities and
ionization parameters (defined as the ratio of ionizing photons to the total
hydrogen density), dust attenuation and emission parameters, and star-formation
histories.
FSPS follows the structure of engines. The Modeler class requires galaxy
physical properties as input and produces as output an Hdf5Handle that
contains the FSPS-generated rest-frame SED for each galaxy and the common
rest-frame wavelength grid. The user can choose the units of the output
rest-frame SEDs by setting the appropriate keyword value. The default behavior
is to output the SEDs in a wavelength grid.
The output rest-frame SEDs constitute the input for the FSPS Creator class.
The latter computes apparent AB magnitudes for a set of user-defined
waveband filters. Notice that the wavelength range spanned by the waveband
filters should be within the SED observed-frame wavelength ranges. A default set
of filters is implemented in rail.fsps, containing the Rubin LSST filters
among others.
- class rail.fsps.FSPSSedModeler
Derived class of Modeler for creating a single galaxy rest-frame SED model using FSPS (Conroy08).
Only the most important parameters are provided via config_options. The remaining ones from FSPS can be provided when creating the rest-frame SED model.
Install FSPS with the following commands:
pip uninstall fsps git clone --recursive https://github.com/dfm/python-fsps.git cd python-fsps python -m pip install . export SPS_HOME=$(pwd)/src/fsps/libfsps
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size (int] (default=10000))
hdf5_groupname (str] (required))
compute_vega_mags ([bool] default=False) – True uses Vega magnitudes versus AB magnitudes
vactoair_flag ([bool] default=False) – If True, output wavelengths in air (rather than vac)
zcontinuous ([int] default=1) – Flag for interpolation in metallicity of SSP before CSP
add_agb_dust_model ([bool] default=True) – Turn on/off adding AGB circumstellar dust contribution to SED
add_dust_emission ([bool] default=True) – Turn on/off adding dust emission contribution to SED
add_igm_absorption ([bool] default=False) – Turn on/off adding IGM absorption contribution to SED
add_neb_emission ([bool] default=False) – Turn on/off nebular emission model based on Cloudy
add_neb_continuum ([bool] default=False) – Turn on/off nebular continuum component
add_stellar_remnants ([bool] default=True) – Turn on/off adding stellar remnants contribution to stellar mass
compute_light_ages ([bool] default=False) – If True then the returned spectra are actually light-weighted ages (in Gyr)
nebemlineinspec ([bool] default=False) – True to include emission line fluxes in spectrum
smooth_velocity ([bool] default=True) – True/False for smoothing in velocity/wavelength space
smooth_lsf ([bool] default=False) – True/False for smoothing SSPs by a wavelength dependent line spread function
cloudy_dust ([bool] default=False) – Switch to include dust in the Cloudy tables
agb_dust ([float] default=1.0) – Scales the circumstellar AGB dust emission
tpagb_norm_type ([int] default=2) – Flag for TP-AGB normalization scheme, default Villaume, Conroy, Johnson 2015 normalization
dell ([float] default=0.0) – Shift in log(L_bol) of the TP-AGB isochrones
delt ([float] default=0.0) – Shift in log(T_eff) of the TP-AGB isochrones
redgb ([float] default=1.0) – Modify weight given to RGB. Only available with BaSTI isochrone set
agb ([float] default=1.0) – Modify weight given to TP-AGB
fcstar ([float] default=1.0) – Fraction of stars that the Padova isochrones identify as Carbon stars
sbss ([float] default=0.0) – Specific frequency of blue straggler stars
fbhb ([float] default=0.0) – Fraction of horizontal branch stars that are blue
pagb ([float] default=1.0) – Weight given to the post–AGB phase
redshifts_key ([str] default=redshifts) – galaxy redshift, dataset keyword name
zmet_key ([str] default=zmet) – The metallicity is specified as an integer ranging between 1 and nz. If zcontinuous > 0 then this parameter is ignored, dataset keyword name
stellar_metallicities_key ([str] default=stellar_metallicity) – galaxy stellar metallicities (log10(Z / Zsun)) dataset keyword name, to be used with zcontinuous > 0,dataset keyword name
pmetals_key ([str] default=pmetals) – The power for the metallicty distribution function,only used if zcontinous=2, dataset keyword name
imf_type ([int] default=1) – IMF type, see FSPS manual, default Chabrier IMF
imf_upper_limit ([float] default=120.0) – The upper limit of the IMF in solar masses
imf_lower_limit ([float] default=0.08) – The lower limit of the IMF in solar masses
imf1 ([float] default=1.3) – log slope of IMF in 0.08<M/Msun<0.5, if imf_type=2
imf2 ([float] default=2.3) – log slope of IMF in 0.5<M/Msun<1, if imf_type=2
imf3 ([float] default=2.3) – log slope of IMF in M/Msun>1, if imf_type=2
vdmc ([float] default=0.08) – IMF parameter defined in van Dokkum (2008). Only used if imf_type=3
mdave ([float] default=0.5) – IMF parameter defined in Dave (2008). Only used if imf_type=4.
evtype ([int] default=-1) – Compute SSPs for only the given evolutionary type. All phases used when set to -1.
use_wr_spectra ([int] default=1) – Turn on/off the WR spectral library
logt_wmb_hot ([float] default=0.0) – Use the Eldridge (2017) WMBasic hot star library above this value of log(T_eff) or 25,000K,whichever is larger
masscut ([float] default=150.0) – Truncate the IMF above this value
velocity_dispersions_key ([str] default=stellar_velocity_dispersion) – stellar velocity dispersions (km/s), dataset keyword name
min_wavelength ([float] default=3000) – minimum rest-frame wavelength
max_wavelength ([float] default=10000) – maximum rest-frame wavelength
gas_ionizations_key ([str] default=gas_ionization) – gas ionization values dataset keyword name
gas_metallicities_key ([str] default=gas_metallicity) – gas metallicities (log10(Zgas / Zsun)) dataset keyword name
igm_factor ([float] default=1.0) – Factor used to scale the IGM optical depth
sfh_type ([int] default=0) – star-formation history type, see FSPS manual, default SSP
tau_key ([str] default=tau) – Defines e-folding time for the SFH, in Gyr. Only used if sfh=1 or sfh=4, dataset keyword name
const_key ([str] default=const) – Defines the constant component of the SFH, Only used if sfh=1 or sfh=4, dataset keyword name
sf_start_key ([str] default=sf_start) – Start time of the SFH, in Gyr. Only used if sfh=1 or sfh=4 or sfh=5, dataset keyword name
sf_trunc_key ([str] default=sf_trunc) – Truncation time of the SFH, in Gyr. Only used if sfh=1 or sfh=4 or sfh=5, dataset keyword name
stellar_ages_key ([str] default=stellar_age) – galaxy stellar ages (Gyr),dataset keyword name
fburst_key ([str] default=fburst) – Defines the fraction of mass formed in an instantaneous burst of star formation. Only used if sfh=1 or sfh=4,dataset keyword name
tburst_key ([str] default=tburst) – Defines the age of the Universe when the burst occurs. If tburst > tage then there is no burst. Only used if sfh=1 or sfh=4, dataset keyword name
sf_slope_key ([str] default=sf_slope) – For sfh=5, this is the slope of the SFR after time sf_trunc, dataset keyword name
dust_type ([int] default=2) – attenuation curve for dust type, see FSPS manual, default Calzetti
dust_tesc ([float] default=7.0) – Stars younger than dust_tesc are attenuated by both dust1 and dust2, while stars older are attenuated by dust2 only. Units are log(yrs)
dust_birth_cloud_key ([str] default=dust1_birth_cloud) – dust parameter describing young stellar light attenuation (dust1 in FSPS), dataset keyword name
dust_diffuse_key ([str] default=dust2_diffuse) – dust parameters describing old stellar light attenuation (dust2 in FSPS) dataset keyword name
dust_clumps ([int] default=-99) – Dust parameter describing the dispersion of a Gaussian PDF density distribution for the old dust. Setting this value to -99.0 sets the distribution to a uniform screen, values other than -99 are no longer supported
frac_nodust ([float] default=0.0) – Fraction of starlight that is not attenuated by the diffuse dust component
frac_obrun ([float] default=0.0) – Fraction of the young stars (age < dust_tesc) that are not attenuated by dust1 and that do not contribute to any nebular emission, representing runaway OB stars or escaping ionizing radiation. These stars are still attenuated by dust2.
dust_index_key ([str] default=dust_index) – Power law index of the attenuation curve. Only used when dust_type=0, dataset keyword name
dust_powerlaw_modifier_key ([str] default=dust_calzetti_modifier) – power-law modifiers to the shape of the Calzetti et al. (2000) attenuation curve (dust1_index),dataset keyword name
mwr_key ([str] default=mwr) – The ratio of total to selective absorption which characterizes the MW extinction curve: RV=AV/E(B-V), used when dust_type=1,dataset keyword name
uvb_key ([str] default=uvb) – Parameter characterizing the strength of the 2175A extinction feature with respect to the standard Cardelli et al. determination for the MW. Only used when dust_type=1,dataset keyword name
wgp1_key ([str] default=wgp1) – Integer specifying the optical depth in the Witt & Gordon (2000) models. Values range from 1 − 18, used only whendust_type=3, dataset keyword name
wgp2 ([int] default=1) – Integer specifying the type of large-scale geometry and extinction curve. Values range from 1-6, used only when dust_type=3
wgp3 ([int] default=1) – Integer specifying the local geometry for the Witt & Gordon (2000) dust models, used only when dust_type=3
dust_emission_gamma_key ([str] default=dust_gamma) – Relative contributions of dust heated at Umin, parameter of Draine and Li (2007) dust emission modeldataset keyword name
dust_emission_umin_key ([str] default=dust_umin) – Minimum radiation field strengths, parameter of Draine and Li (2007) dust emission model, dataset keyword name
dust_emission_qpah_key ([str] default=dust_qpah) – Grain size distributions in mass in PAHs, parameter of Draine and Li (2007) dust emission model,dataset keyword name
fraction_agn_bol_lum_key ([str] default=f_agn) – Fractional contributions of AGN wrt stellar bolometric luminosity, dataset keyword name
agn_torus_opt_depth_key ([str] default=tau_agn) – Optical depths of the AGN dust torii dataset keyword name
tabulated_sfh_key ([str] default=tabulated_sfh) – tabulated SFH dataset keyword name
tabulated_lsf_key ([str] default=tabulated_lsf) – tabulated LSF dataset keyword name
physical_units ([bool] default=False) – A parameter
msg (str] (default=False (True) for rest-frame spectra in units ofLsun/Hz (erg/s/Hz)))
restframe_wave_key ([str] default=restframe_wavelengths) – Rest-frame wavelength keyword name of the output hdf5 dataset
restframe_sed_key ([str] default=restframe_seds) – Rest-frame SED keyword name of the output hdf5 dataset
input (Hdf5Handle (INPUT))
model (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
This function initializes the FSPSSedModeler class and checks that the provided parameters are within the allowed ranges.
- Parameters:
args
comm
- classmethod __new__(*args, **kwargs)
- class rail.fsps.FSPSPhotometryCreator
Derived class of Creator that generate synthetic photometric fsps_default_data from the rest-frame SED model generated with the FSPSSedModeler class. The user is required to provide galaxy redshifts and filter information in an .npy format for the code to run. The restframe SEDs are stored in a pickle file or passed as ModelHandle. Details of what each file should contain are explicited in config_options. The output is a Fits table containing magnitudes.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
redshift_key ([str] default=redshifts) – Redshift keyword name of the hdf5 dataset containing rest-frame SEDs
restframe_sed_key ([str] default=restframe_seds) – Rest-frame SED keyword name of the hdf5 dataset containing rest-frame SEDs
restframe_wave_key ([str] default=wavelength) – Rest-frame wavelengths keyword name of thehdf5 dataset containing rest-frame SEDs
apparent_mags_key ([str] default=apparent_mags) – Apparent magnitudes keyword name of the output hdf5 dataset
filter_folder ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/fsps_default_data/filters) – Folder containing filter transmissions
instrument_name ([str] default=lsst) – Instrument name as prefix to filter transmission files
wavebands ([str] default=u,g,r,i,z,y) – Comma-separated list of wavebands
filter_wave_key ([str] default=wave)
filter_transm_key: [str] default=transmission
- Om0: [float] default=0.3
Omega matter at current time
- Ode0: [float] default=0.7
Omega dark energy at current time
- w0: [float] default=-1
Dark energy equation-of-state parameter at current time
- wa: [float] default=0.0
Slope dark energy equation-of-state evolution with scale factor
- h: [float] default=0.7
Dimensionless hubble constant
- use_planck_cosmology: [bool] default=False
True to overwrite the cosmological parameters to their Planck2015 values
- physical_units: [bool] default=False
A parameter
msg: str] (default=False (True) for rest-frame spectra in units ofLsun/Hz (erg/s/Hz))
model: Hdf5Handle (INPUT)
output: Hdf5Handle (OUTPUT)
- __init__(args, **kwargs)
Initialize class. The _b and _c tuples for jax are composed of None or 0, depending on whether you don’t or do want the array axis to map over for all arguments. :param args: :param comm:
- classmethod __new__(*args, **kwargs)
DSPS (Differentiable Stellar Population Synthesis)
RAIL Package: https://github.com/LSSTDESC/rail_dsps
dsps is a module that creates an interface in RAIL to the code DSPS
(Differentiable Stellar Population Synthesis, Hearin et al. 2023). DSPS is
implemented natively in the JAX library as its main aim is to produce
differentiable predictions for the SED of a galaxy based on SPS. The
implementation in JAX allows DSPS to be a factor of 5 faster than standard SPS
codes, such as FSPS, and more than 300 times faster, if run on a modern GPU.
DSPS does not come with stellar population templates; they must be provided by
the user. The code contains a series of convenience functions that allow the
user to generate stellar population templates with FSPS. If no templates are
supplied, the implementation in RAIL automatically downloads a set of
FSPS-generated stellar population templates.
The Modeler class of dsps requires as input a catalog of galaxy physical
properties in the form of Hdf5Handles. In particular, the user provides, for
each galaxy, a star-formation history, a grid of Universe age over which the
stellar mass build-up takes place, and a value for the mean and scatter of the
stellar metallicity distribution. The output is an Hdf5Handle that contains
galaxy rest-frame SEDs, produced over the stellar population template wavelength
grid.
The Creator class of dsps uses the output rest-frame SEDs to compute
apparent and rest-frame AB magnitudes for a set of user-defined filters.
Rubin-LSST filters are present in the default filter suite. The magnitudes are
computed using the appropriate functions implemented in DSPS that, much like
the SED generation, can take advantage of multiprocessing capabilities.
- class rail.dsps.DSPSSingleSedModeler
Derived class of Modeler for creating a single galaxy rest-frame SED model using DSPS v3. (Hearin+21). SPS calculations are based on a set of template SEDs of simple stellar populations (SSPs). Supplying such templates is outside the planned scope of the DSPS package, and so they will need to be retrieved from some other library. For example, the FSPS library supplies such templates in a convenient form.
The input galaxy properties, such as star-formation histories and metallicities, need to be supplied via an hdf5 table.
The user-provided metallicity grid should be consistently defined with the metallicity of the templates SEDs. Users should be cautious in the use of the cosmic time grid. The time resolution strongly depends on the user scientific aim.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
ssp_templates_file ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/dsps_default_data/ssp_data_fsps_v3.2_lgmet_age.h5) – hdf5 file storing the SSP libraries used to create SEDs
redshift_key ([str] default=redshifts) – Redshift keyword name of the hdf5 dataset
cosmic_time_grid_key ([str] default=cosmic_time_grid) – Cosmic time grid keyword name of the hdf5 dataset, this is the grid of Universe age over which the stellar mass build-up takes place in units of Gyr
star_formation_history_key ([str] default=star_formation_history) – Star-formation history keyword name of the hdf5 dataset, this is the star-formation history of the galaxy in units of Msun/yr
stellar_metallicity_key ([str] default=stellar_metallicity) – Stellar metallicity keyword name of the hdf5 dataset, this is the stellar metallicity in units of log10(Z)
stellar_metallicity_scatter_key ([str] default=stellar_metallicity_scatter) – Stellar metallicity scatter keyword name of the hdf5 dataset, this is lognormal scatter in the metallicity distribution function
restframe_sed_key ([str] default=restframe_sed) – Rest-frame SED keyword name of the output hdf5 dataset
default_cosmology ([bool] default=True) – True to use default DSPS cosmology. If False,Om0, w0, wa, h need to be supplied in the fit_model function
min_wavelength ([float] default=250) – Minimum output rest-frame wavelength
max_wavelength ([float] default=12000) – Maximum output rest-frame wavelength
input (Hdf5Handle (INPUT))
model (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
Initialize SedModeler class. If the SSP templates are not provided by the user, they are automatically downloaded from the public NERSC directory. These default templates are created with default FSPS values, with gas emission at fixed gas solar metallicity value.
- Parameters:
args
comm
- classmethod __new__(*args, **kwargs)
- class rail.dsps.DSPSPopulationSedModeler
Derived class of Modeler for creating a population of galaxy rest-frame SED models using DSPS v3. (Hearin+21). SPS calculations are based on a set of template SEDs of simple stellar populations (SSPs). Supplying such templates is outside the planned scope of the DSPS package, and so they will need to be retrieved from some other library. For example, the FSPS library supplies such templates in a convenient form.
The input galaxy properties, such as star-formation histories and metallicities, need to be supplied via an hdf5 table.
The user-provided metallicity grid should be consistently defined with the metallicity of the templates SEDs. Users should be cautious in the use of the cosmic time grid. The time resolution strongly depends on the user scientific aim. jax serially execute the computations on CPU on single core, for CPU parallelization you need MPI. If GPU is used, jax natively and automatically parallelize the execution.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
ssp_templates_file ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/dsps_default_data/ssp_data_fsps_v3.2_lgmet_age.h5) – hdf5 file storing the SSP libraries used to create SEDs
redshift_key ([str] default=redshift) – Redshift keyword name of the hdf5 dataset
cosmic_time_grid_key ([str] default=cosmic_time_grid) – Cosmic time grid keyword name of the hdf5 dataset, this is the grid of Universe age over which the stellar mass build-up takes place in units of Gyr
star_formation_history_key ([str] default=star_formation_history) – Star-formation history keyword name of the hdf5 dataset, this is the star-formation history of the galaxy in units of Msun/yr
stellar_metallicity_key ([str] default=stellar_metallicity) – Stellar metallicity keyword name of the hdf5 dataset, this is the stellar metallicity in units of log10(Z)
stellar_metallicity_scatter_key ([str] default=stellar_metallicity_scatter) – Stellar metallicity scatter keyword name of the hdf5 dataset, this is lognormal scatter in the metallicity distribution function
restframe_sed_key ([str] default=restframe_seds) – Rest-frame SED keyword name of the output hdf5 dataset
default_cosmology ([bool] default=True) – True to use default DSPS cosmology. If False,Om0, w0, wa, h need to be supplied in the fit_model function
min_wavelength ([float] default=250) – Minimum output rest-frame wavelength
max_wavelength ([float] default=12000) – Maximum output rest-frame wavelength
input (Hdf5Handle (INPUT))
model (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
Initialize SedModeler class. If the SSP templates are not provided by the user, they are automatically downloaded from the public NERSC directory. These default templates are created with default FSPS values, with gas emission at fixed gas solar metallicity value. The _a tuple for jax is composed of None or 0, depending on whether you don’t or do want the array axis to map over for all arguments.
- classmethod __new__(*args, **kwargs)
- class rail.dsps.DSPSPhotometryCreator
Derived class of Creator that generate synthetic absolute and apparent magnitudes from one or more SED models generated with the DSPSSingleSedModeler or DSPSPopulationSedModeler classes. It accepts as input Hdf5Handles containing the rest-frame SEDs in units of Lsun/Hz and outputs an Hdf5Handle containing sequential indices, absolute and apparent magnitudes for each galaxy. Photometric quantities are computed for the filters defined in the configuration file.
jax serially execute the computations on CPU on single core, for CPU parallelization you need MPI. If GPU is used, jax natively and automatically parallelize the execution.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
redshift_key ([str] default=redshifts) – Redshift keyword name of the hdf5 dataset containing rest-frame SEDs
restframe_sed_key ([str] default=restframe_seds) – Rest-frame SED keyword name of the hdf5 dataset containing rest-frame SEDs
absolute_mags_key ([str] default=rest_frame_absolute_mags) – Absolute magnitudes keyword name of the output hdf5 dataset
apparent_mags_key ([str] default=apparent_mags) – Apparent magnitudes keyword name of the output hdf5 dataset
filter_folder ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/dsps_default_data/filters) – Folder containing filter transmissions
instrument_name ([str] default=lsst) – Instrument name as prefix to filter transmission files
wavebands ([str] default=u,g,r,i,z,y) – Comma-separated list of wavebands
min_wavelength ([float] default=250) – Minimum input rest-frame wavelength SEDs
max_wavelength ([float] default=12000) – Maximum input rest-frame wavelength SEDs
ssp_templates_file ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/dsps_default_data/ssp_data_fsps_v3.2_lgmet_age.h5) – hdf5 file storing the SSP libraries used to create SEDs
default_cosmology ([bool] default=True) – True to use default DSPS cosmology. If False,Om0, w0, wa, h need to be supplied in the sample function
model (Hdf5Handle (INPUT))
output (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
Initialize DSPSPhotometryCreator class. If the SSP templates are not provided by the user, they are automatically downloaded from the public NERSC directory. These default templates are created with default FSPS values, with gas emission at fixed gas solar metallicity value. The _b and _c tuples for jax are composed of None or 0, depending on whether you don’t or do want the array axis to map over for all arguments.
- Parameters:
args
comm
- classmethod __new__(*args, **kwargs)
PZFlow Engine
RAIL Package: https://github.com/LSSTDESC/rail_pzflow
PZFlow is a generative model that simulates galaxy catalogs using normalizing
flows. Normalizing flows learn differentiable mappings between complex data
distributions and a simple latent distribution, for example, a Normal
distribution, hence the name normalizing flow. In the creation module, a
normalizing flow is trained to map the distribution of galaxy colors and
redshifts onto a simple latent distribution. New galaxy catalogs can then be
simulated by sampling from the latent distribution and applying the inverse flow
to the samples. In addition, because the samples are generated by sampling from
a distribution we have direct access to, there is a natural notion of a true
redshift distribution for each galaxy in the catalog. For more information, see
Crenshaw et al. 2024. Note that PZFlow is also used to perform photo-z
estimation.
- class rail.pzflow.FlowModeler
Modeler wrapper for a PZFlow Flow object.
This class trains the flow.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([int] default=0) – The random seed for training.
phys_cols ([dict] default={'redshift': [0, 3]}) – Names of non-photometry columns and their corresponding [min, max] values.
phot_cols ([dict] default={'mag_u_lsst': [17, 35], 'mag_g_lsst': [16, 32], 'mag_r_lsst': [15, 30], 'mag_i_lsst': [15, 30], 'mag_z_lsst': [14, 29], 'mag_y_lsst': [14, 28]}) – Names of photometry columns and their corresponding [min, max] values.
calc_colors ([dict] default={'ref_column_name': 'mag_i_lsst'}) – Whether to internally calculate colors (if phot_cols are magnitudes). Assumes that you want to calculate colors from adjacent columns in phot_cols. If you do not want to calculate colors, set False. Else, provide a dictionary {‘ref_column_name’: band}, where band is a string corresponding to the column in phot_cols you want to save as the overall galaxy magnitude.
spline_knots ([int] default=16) – The number of spline knots in the normalizing flow.
num_training_epochs ([int] default=30) – The number of training epochs.
input (TableHandle (INPUT))
model (FlowHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor
Does standard Modeler initialization.
- classmethod __new__(*args, **kwargs)
- class rail.pzflow.FlowPosterior
PosteriorCalculator wrapper for a PZFlow Flow object
data : pd.DataFrame Pandas dataframe of the data on which the posteriors are conditioned. Must have all columns in self.flow.data_columns, *except* for the column specified for the posterior (see below). column : str Name of the column for which the posterior is calculated. Must be one of the columns in self.flow.data_columns. However, whether or not this column is present in `data` is irrelevant. grid : np.ndarray Grid over which the posterior is calculated. err_samples : int, optional Number of samples from the error distribution to average over for the posterior calculation. If provided, Gaussian errors are assumed, and method will look for error columns in `inputs`. Error columns must end in `_err`. E.g. the error column for the variable `u` must be `u_err`. Zero error assumed for any missing error columns. seed: int, optional Random seed for drawing samples from the error distribution. marg_rules : dict, optional Dictionary with rules for marginalizing over missing variables. The dictionary must contain the key "flag", which gives the flag that indicates a missing value. E.g. if missing values are given the value 99, the dictionary should contain {"flag": 99}. The dictionary must also contain {"name": callable} for any variables that will need to be marginalized over, where name is the name of the variable, and callable is a callable that takes the row of variables and returns a grid over which to marginalize the variable. E.g. {"y": lambda row: np.linspace(0, row["x"], 10)}. Note: the callable for a given name must *always* return an array of the same length, regardless of the input row. DEFAULT: the default marg_rules dict is {"flag": np.nan, "u": np.linspace(25, 31, 10),} batch_size: int, default=None Size of batches in which to calculate posteriors. If None, all posteriors are calculated simultaneously. This is faster, but requires more memory. nan_to_zero : bool, default=True Whether to convert NaN's to zero probability in the final pdfs.- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
column ([str] (required)) – Column to compute posterior for
grid ([list] default=[]) – Grid over which the posterior is calculated
err_samples ([int] default=10) – A parameter
seed ([int] default=12345) – A parameter
marg_rules ([dict] default={'flag': nan, 'mag_u_lsst': <function FlowPosterior.<lambda> at 0x7ab094c5f110>}) – A parameter
batch_size (int] (default=10000))
nan_to_zero (bool] (default=True))
model (FlowHandle (INPUT))
input (PqHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor
Does standard PosteriorCalculator initialization
- classmethod __new__(*args, **kwargs)
Degraders
Each engine produces a catalog from some input information, but turning the
truth catalog into realistically imperfect observations necessitates additional
steps in a forward model. A degrader may be a subclass of either
rail.creation.noisifier (later referred to as noisifier) or
rail.creation.selector (later referred to as selector), the first of
which modifies data in place and the second of which removes rows from a
catalog. The only exception is the blending degrader, which changes both. We
provide several survey-specific shortcuts to mimic the selection functions of
precursor data sets. Specifically, the noisifier superclass imposes
realistically complex noise and bias to the (𝑧, photometry) columns, and the
selector superclass introduces biased selection on the sample to mimic, e.g., an
incomplete spectroscopic training sample.
LSST Error Model
The LSSTErrorModel is a wrapper of the PhotErr photometric error model (Crenshaw et
al. 2024). PhotErr is a generalization of the error model described in Ivezić et al.
(2019) that includes multiple methods for modeling photometric errors, non-detections,
and extended source errors. In addition to photometric error model for LSST, we also
include models for Euclid (Euclid Collaboration et al. 2022) and Nancy Grace Roman
(Spergel et al. 2015) space telescopes. The magnitude errors are estimated based on the
input galaxy properties and the survey conditions, such as 5𝜎 depth and seeing, and
each galaxy has noise added to its magnitude according to a Gaussian distribution with
mean zero and standard deviation equal to its magnitude error. For more information, see
Appendix B of Crenshaw et al. (2024).
- class rail.astro_tools.PhotoErrorModel
The Base Model for photometric errors.
This is a wrapper around the error model from PhotErr. The parameter docstring below is dynamically added by the installed version of PhotErr:
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.LSSTErrorModel
The LSST Error model, defined by peLsstErrorParams and peLsstErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.RomanErrorModel
The Roman Error model, defined by peRomanErrorParams and peRomanErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.RomanWideErrorModel
The Roman WideError model, defined by peRomanWideErrorParams and peRomanWideErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.RomanMediumErrorModel
The Roman Medium Error model, defined by peRomanMediumErrorParams and peRomanMediumErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.RomanDeepErrorModel
The Roman Deep Error model, defined by peRomanDeepErrorParams and peRomanDeepErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.RomanUltraDeepErrorModel
The Roman UltraDeep Error model, defined by peRomanUltraDeepErrorParams and peRomanUltraDeepErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.EuclidErrorModel
The Euclid Error model, defined by peEuclidErrorParams and peEuclidErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.EuclidWideErrorModel
The Euclid Wide Error model, defined by peEuclidWideErrorParams and peEuclidWideErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.EuclidDeepErrorModel
The Euclid Deep Error model, defined by peEuclidDeepErrorParams and peEuclidDeepErrorModel
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
Observing Condition Degrader
This degrader produces observed magnitude and magnitude errors for the truth sample,
based on the input survey condition maps (Hang et al. 2024). The user provides a series
of survey condition maps in HEALPix (Górski et al. 2005) format with specified
𝑁side, e.g. the 5𝜎 depth in each band. The galaxies in the truth sample will be
assigned survey conditions corresponding to their HEALPix pixel, either based on
their coordinates in the original catalog, or randomly if only photometry is available
(e.g., generated from the engines). In the latter case, a weight map can be specified to
adjust the number of galaxies assigned to each pixel. A key input for
ObservingConditionDegrader is map_dict. This is a dictionary containing keys
with the same names as parameters for LSSTErrorModel. Under each key, one can pass a
series of paths for the survey condition maps for each band, or, if any quantity is held
constant throughout the footprint, one can also pass a float number. The degrader then
calls PhotErr to compute noisy magnitudes for each galaxy in each HEALPix pixel. The
output of this module is a table containing degraded magnitudes, magnitude errors, RA,
Dec, and the HEALPix pixel index of each galaxy.
- class rail.astro_tools.ObsCondition
Photometric errors based on observation conditions
This degrader calculates spatially-varying photometric errors using input survey condition maps. The error is based on the LSSTErrorModel from the PhotErr python package.
mask: str, optional Path to the mask covering the survey footprint in HEALPIX format. Notice that all negative values will be set to zero. weight: str, optional Path to the weights HEALPIX format, used to assign sample galaxies to pixels. Default is weight="", which uses uniform weighting. tot_nVis_flag: bool, optional If any map for nVisYr are provided, this flag indicates whether the map shows the total number of visits in nYrObs (tot_nVis_flag=True), or the average number of visits per year (tot_nVis_flag=False). The default is set to True. map_dict: dict, optional A dictionary that contains the paths to the survey condition maps in HEALPIX format. This dictionary uses the same arguments as LSSTErrorModel (from PhotErr). The following arguments, if supplied, may contain either a single number (as in the case of LSSTErrorModel), or a path: [m5, nVisYr, airmass, gamma, msky, theta, km, tvis, EBV] For the following keys: [m5, nVisYr, gamma, msky, theta, km] numbers/paths for specific bands must be passed. Example: {"m5": {"u": path, ...}, "theta": {"u": path, ...},} Other LSSTErrorModel parameters can also be passed in this dictionary (e.g. a necessary one may be [nYrObs] or the survey condition maps). If any argument is not passed, the default value in PhotErr's LsstErrorModel is adopted.- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
nside ([int] default=128) – nside for the input maps in HEALPIX format.
mask ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/creation/degraders/../../examples_data/creation_data/data/survey_conditions/DC2-mask-neg-nside-128.fits) – mask for the input maps in HEALPIX format.
weight ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/creation/degraders/../../examples_data/creation_data/data/survey_conditions/DC2-dr6-galcounts-i20-i25.3-nside-128.fits) – weight for assigning pixels to galaxies in HEALPIX format.
tot_nVis_flag ([bool] default=True) – flag indicating whether nVisYr is the total or average per year if supplied.
random_seed ([int] default=42) – random seed for reproducibility
map_dict ([dict] default={'m5': {'i': '/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/creation/degraders/../../examples_data/creation_data/data/survey_conditions/minion_1016_dc2_Median_fiveSigmaDepth_i_and_nightlt1825_HEAL.fits'}, 'nYrObs': 5.0}) – dictionary containing the paths to the survey condition maps and/or additional LSSTErrorModel parameters.
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
Spectroscopic Degraders
SpectroscopicDegraders contains two simple degraders that simulate systematic errors
associated with the presence of spectroscopic redshifts in spectroscopic training
catalogs.
The first is InvRedshiftIncompleteness. It is a toy model for redshift
incompleteness – i.e., the failure of a particular spectrograph to obtain a redshift
estimate for a particular set of galaxies. It takes an input catalog and keeps all the
galaxies below a configurable redshift threshold while randomly removing galaxies above
it. The probability that a redshift \(z\) galaxy is kept is:
where \(z_\mathrm{th}\) is the threshold redshift.
The other degrader is LineConfusion, which simulates redshift errors due to the
confusion of emission lines. For example, if the OII line at \(3727~\mathring{\mathrm{A}}\) was
misidentified as the OIII line at \(5007~\mathring{\mathrm{A}}\), the assigned spectroscopic redshift
would be greater than the true redshift (Newman et al. 2013). The inputs of this
degrader are a true and wrong redshift, and an error rate. The degrader then
randomly simulates line confusion, ignoring galaxies for which the misidentification
would result in a negative redshift (which can occur when the wrong wavelength is
shorter than the true wavelength).
- class rail.astro_tools.LineConfusion
Degrader that simulates emission line confusion.
degrader = LineConfusion(true_wavelen=3727, wrong_wavelen=5007, frac_wrong=0.05)
is a degrader that misidentifies 5% of OII lines (at 3727 angstroms) as OIII lines (at 5007 angstroms), which results in a larger spectroscopic redshift.
Note that when selecting the galaxies for which the lines are confused, the degrader ignores galaxies for which this line confusion would result in a negative redshift, which can occur for low redshift galaxies when wrong_wavelen < true_wavelen.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([type not specified] default=None) – Set to an int to force reproducible results.
true_wavelen ([float] (required)) – wavelength of the true emission line
wrong_wavelen ([float] (required)) – wavelength of the wrong emission line
frac_wrong ([float] (required)) – fraction of galaxies with confused emission lines
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.InvRedshiftIncompleteness
Degrader that simulates incompleteness with a selection function inversely proportional to redshift.
The survival probability of this selection function is p(z) = min(1, z_p/z), where z_p is the pivot redshift.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
pivot_redshift ([float] (required)) – redshift at which the incompleteness begins
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
- classmethod __new__(*args, **kwargs)
QuantityCut
This degrader provides a trimmed version of the input catalog based on selection cuts applied to the catalog quantities. The user provides the parameter cuts, which is a dictionary with keys being the columns to which the selection is to be applied (e.g., the 𝑖-band magnitude), and the values being the specific cuts. Two types of values can be provided: a single float number (e.g., 25.3), which is interpreted as a maximum value (i.e., the cut will remove samples with 𝑖 > 25.3), and a tuple (e.g., (17, 25.3)), which is interpreted as a range within which the sample is selected (i.e., the selected sample has 17 < 𝑖 < 25.3). When multiple cuts are applied at the same time, only the intersection of selected samples of each cut will be kept in the output.
- class rail.creation.degraders.quantityCut.QuantityCut
Degrader that applies a cut to the given columns.
Note that if a galaxy fails any of the cuts on any one of its columns, that galaxy is removed from the sample.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
cuts ([dict] (required)) – Cuts to apply
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor.
Performs standard Degrader initialization as well as defining the cuts to be applied.
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Spectroscopic Selectors
The SpectroscopicSelection degrader applies the selection for a spectroscopic
survey. It provides tailored catalogs that match a particular spectroscopic survey for
subsequent calibration steps. It can also be used to generate selected mock catalogs
used as realistic reference samples. The selection criteria are cuts on magnitudes or
colors adopted for the associated spectroscopic survey targeting. The current available
selectors are for VVDSf02 (Le Fèvre et al. 2005), zCOSMOS (Lilly et al. 2009), GAMA
(Driver et al. 2011), BOSS (Dawson et al. 2013), and DEEP2 (Newman et al. 2013).
SpectroscopicSelection requires a 2-dimensional spectroscopic redshift success rate as
a function of two variables (often two of magnitude, color, or redshift), specific to
the redshift survey for which selection is being emulated. The degrader will draw the
appropriate fraction of samples from the input data and return an incomplete sample.
Additional redshift cuts based on percentile can be applied when using a color-based
redshift cut.
Similar functionality is provided by GridSelection (Moskowitz et al. 2024), which
can be used to model spectroscopic success rates for the training sets used for the
second data release of the Hyper Suprime Cam Subaru Strategic Program (HSC; Aihara et
al. 2019). Given a 2-dimensional grid of spectroscopic success ratio as a function of
two variables (often magnitude or color), the degrader will draw the appropriate
fraction of samples from the input data and return incomplete sample. Additional
redshift cuts can also be applied, where all redshifts above the cutoff are removed. In
addition to the default HSC grid, RAIL accepts user-defined setting files for the
success ratio grids appropriate for other surveys.
- class rail.astro_tools.SpecSelection
The super class of spectroscopic selections.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.SpecSelection_GAMA
The class of spectroscopic selections with GAMA.
The GAMA survey covers an area of 286 deg^2, with ~238000 objects.
The necessary column is r band.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.SpecSelection_BOSS
The class of spectroscopic selections with BOSS.
BOSS selection function is based on http://www.sdss3.org/dr9/algorithms/boss_galaxy_ts.php
The selection has changed slightly compared to Dawson+13.
BOSS covers an area of 9100 deg^2 with 893,319 galaxies.
For BOSS selection, the data should at least include gri bands.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.SpecSelection_DEEP2
The class of spectroscopic selections with DEEP2.
DEEP2 has a sky coverage of 2.8 deg^2 with ~53000 spectra.
For DEEP2, one needs R band magnitude, B-R/R-I colors–which are not available for the time being, so we use LSST gri bands now. When the conversion degrader is ready, this subclass will be updated accordingly.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.SpecSelection_VVDSf02
The class of spectroscopic selections with VVDSf02.
It covers an area of 0.5 deg^2 with ~10000 sources.
Necessary columns are i band magnitude and redshift.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.SpecSelection_zCOSMOS
The class of spectroscopic selections with zCOSMOS.
It covers an area of 1.7 deg^2 with ~20000 galaxies.
For zCOSMOS, the data should at least include i band and redshift.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.astro_tools.SpecSelection_HSC
The class of spectroscopic selections with HSC.
For HSC, the data should at least include giz bands and redshift.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
N_tot ([int] default=10000) – Number of selected sources
nondetect_val ([float] default=99.0) – value to be removed for non detects
downsample ([bool] default=True) – If true, downsample the selected sources into a total number of N_tot
success_rate_dir ([str] default=/home/docs/checkouts/readthedocs.org/user_builds/rail-hub/conda/stable/lib/python3.14/site-packages/rail/examples_data/creation_data/data/success_rate_data) – The path to the directory containing success rate files.
percentile_cut ([int] default=100) – cut redshifts above this percentile
colnames ([dict] default={'u': 'mag_u_lsst', 'g': 'mag_g_lsst', 'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst', 'y': 'mag_y_lsst', 'redshift': 'redshift'}) –
- a dictionary that includes necessary columns (magnitudes, colors and
redshift) for selection. For magnitudes, the keys are ugrizy; for colors, the keys are, for example, gr standing for g-r; for redshift, the key is ‘redshift’
random_seed ([int] default=42) – random seed for reproducibility
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
. .autoclass: rail.astro_tools.GridSelection
SOMSpecSelector
While GridSelection defines a selection mask in two dimensions, SOMSpecSelector
can take any number of input features with which to define a spectroscopic selection.
This selector takes an initial complete sample (which we will call the input sample) and
return a subset that approximately matches the properties of an incomplete sample (we
will refer to this as the specz sample). The selector operates by taking the list of
features (which must be present in both the input and specz samples) and constructs a
self-organizing map (SOM; Kohonen 1982) from the input data, creating a mapping from the
higher-dimensional feature set to the 2D grid of SOM cells. It then finds the best cell
assignment for each galaxy in both the input and specz samples. The selector builds a
mask as it iterates over all cells, and for each cell returns a random subset of input
objects that lie in that cell that equal in number to specz objects in the cell. If the
cell has more specz objects than are available in the input catalog, then it returns all
that are available. By matching the number of objects cell by cell the selector
naturally mimics the features of the specz sample.
- class rail.creation.degraders.specz_som.SOMSpecSelector
Class that creates a specz sample by training a SOM on data with spec-z, classifying all galaxies from a larger sample via the SOM, then selecting the same number of galaxies in each SOM cell as there are in the specz sample. If fewer galaxies are available in the large sample for a cell, it just takes as many as possible, so you can still mismatch the distribution numbers, i.e. if you have a lot of bright galaxies with speczs from a really wide survey like SDSS and the second dataset does not have the same areal coverage, then there may not be enough bright objects in the second dataset to select, so you will end up with fewer.
For the columns used to construct the SOM, there are two sets of columns, noncolor_cols is a config option where you supply a list of columns that will be used directly in the SOM, e.g. redshift, i-magnitude, etc… color_cols, on the other hand, is a config parameter where the user supplies an ordered list of columns that will be differenced before being used as SOM inputs, e.g. if you supply [‘u’, ‘g’,’r’] then a function in the code will compute u-g and g-r and use those in SOM construction. The code combines the noncolor_cols and color_cols features and all are used in construction of the SOM.
As this degrader inherits from Selector, it simply computes a mask, the Selector parent class code will perform the masking, and will return the final dataset that mimics the input reference sample.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
drop_rows ([bool] default=True) – Drop selected rows from output table
seed ([type not specified] default=None) – Set to an int to force reproducible results.
nondetect_val (float] (default=99.0))
noncolor_cols ([list] default=['i', 'redshift']) – data columns used for SOM, can be a single band ifyou will also be using colordata in ‘color_cols’, or can be as many as you want
noncolor_nondet ([list] default=[28.62, -1.0]) – list of nondetect replacement values for the non-color cols
color_cols ([list] default=['u', 'g', 'r', 'i', 'z', 'y']) – columns that will be differenced to make colors. This will be done in order, so put in increasing WL order
color_nondet ([list] default=[27.79, 29.04, 29.06, 28.62, 27.98, 27.05]) – list of nondetect replacement vals for color columns
som_size ([list] default=[32, 32]) – tuple containing the size (x, y) of the SOM
n_epochs ([int] default=10) – number of training epochs.
spec_data (TableHandle (INPUT))
input (TableHandle (INPUT))
output (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- classmethod __new__(*args, **kwargs)
Blending Degrader
This degrader creates mock unrecognized blends based on source density. Unrecognized blends are sources overlapping too closely in projection and are detected as one object (referred to as ambiguous blends in Dawson et al. 2016). This degrader first searches for close objects that are likely to become unrecognized blends, then merges their fluxes to create one blended object. The source IDs of blend components are saved for references.
The blending components are found by matching the RA and Dec coordinates of an input catalog with itself via a Friends-of-Friends (FoF) algorithm (Mao et al. 2021). The advantage of the FoF algorithm is that it can produce unrecognized blends from multiple sources rather than just pairs. The algorithm groups sources such that within each group, every source is separated from at lease one another group member by an angular distance less than a specified linking length. By setting a small enough linking length (e.g., 1 arcsec), we assume that all group members will be blended into one detection. In the future, we might implement options for a more sophisticated identification of blends using source sizes and shapes. In the current release, this degrader simply sums up fluxes over all group members to create one blended object per group. Note that we do not currently simulate the impact on aperture photometry due to irregular profiles of blends either, but are motivated to conduct such a study in the future.
Note that the truth redshifts of blended objects are ambiguous since they are composed
of multiple objects. We provide several summary columns for the truth: z_brightest
is the redshift of the brightest component; z_mean is the average redshift of all
components; and z_weighted is the flux-weighted average redshift. For blended
objects composed of more than (including) two components, the standard deviation of
redshifts is provided. The decision on the truth redshift is left to the users. For more
complicated truth estimation – e.g., considering the colors of components, as bluer
galaxies tend to have strong emission lines which are often used to infer redshifts from
spectroscopy – users have the option to trace the components with source IDs. The
tutorial blending_degrader_demo illustrates how to match the output catalog with the
source IDs and the input catalog to access more information.
The order of application is particularly important for this degrader. Generally, this degrader should be applied before any selections on the truth catalog, including any magnitude, color, or signal-to-noise ratio cuts. The reason is that bright sources can blend with fainter ones, and two faint sources might blend into a brighter object that enters the target depth selection. For example, a magnitude difference of \(\sim2.5\) translates roughly into a flux contamination of 10%. However, applying this degrader to the original truth catalog without any cuts can be a computational burden, because the truth catalog is often much larger than the target-depth catalog. To mitigate this issue, one can use a magnitude cut to decrease the target depth by {an arbitrary threshold (e.g., 2 or 3 magnitudes)} before running this degrader.
While preliminary studies have addressed some aspects of blending on photo-z (e.g., Nourbakhsh et al. 2022), a thorough quantitative exploration of this topic will be important to develop a deeper understanding of the issue and its impacts on various science cases.
- class rail.creation.degraders.unrec_bl_model.UnrecBlModel
Model for Creating Unrecognized Blends.
Finding objects nearby each other. Merge them into one blended Use Friends of Friends for matching. May implement shape matching in the future. Take avergaged Ra and Dec for blended source, and sum up fluxes in each band. May implement merged shapes in the future.
Requires gcc, which depending on your installation, may be difficult for the caller (FoFCatalogMatching dependency fast3tree) to find. Conda-installed gcc seems to fix this.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
seed ([int] default=12345) – Random number seed
ra_label ([str] default=ra) – ra column name
dec_label ([str] default=dec) – dec column name
linking_lengths ([float] default=1.0) – linking_lengths for FoF matching
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
zp_dict ([dict] default={'u': 12.65, 'g': 14.69, 'r': 14.56, 'i': 14.38, 'z': 13.99, 'y': 13.02}) – magnitude zeropoints dictionary
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
match_size ([bool] default=False) – consider object size for finding blends
match_shape ([bool] default=False) – consider object shape for finding blends
obj_size ([str] default=obj_size) – object size column name
a ([str] default=semi_major) – semi major axis column name
b ([str] default=semi_minor) – semi minor axis column name
theta ([str] default=orientation) – orientation angle column name
input (PqHandle (INPUT))
output (PqHandle (OUTPUT))
compInd (PqHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)