Estimation
Estimation is a type of RAIL stage which uses photometric data to generate photometric redshift pdfs, both for individual galaxies and entire catalogs. Estimation stages use estimators to produce per-galaxy photo-z PDFs, summarizers to produce redshift distributions, and classifiers to produce per-galaxy IDs for tomographic binning.
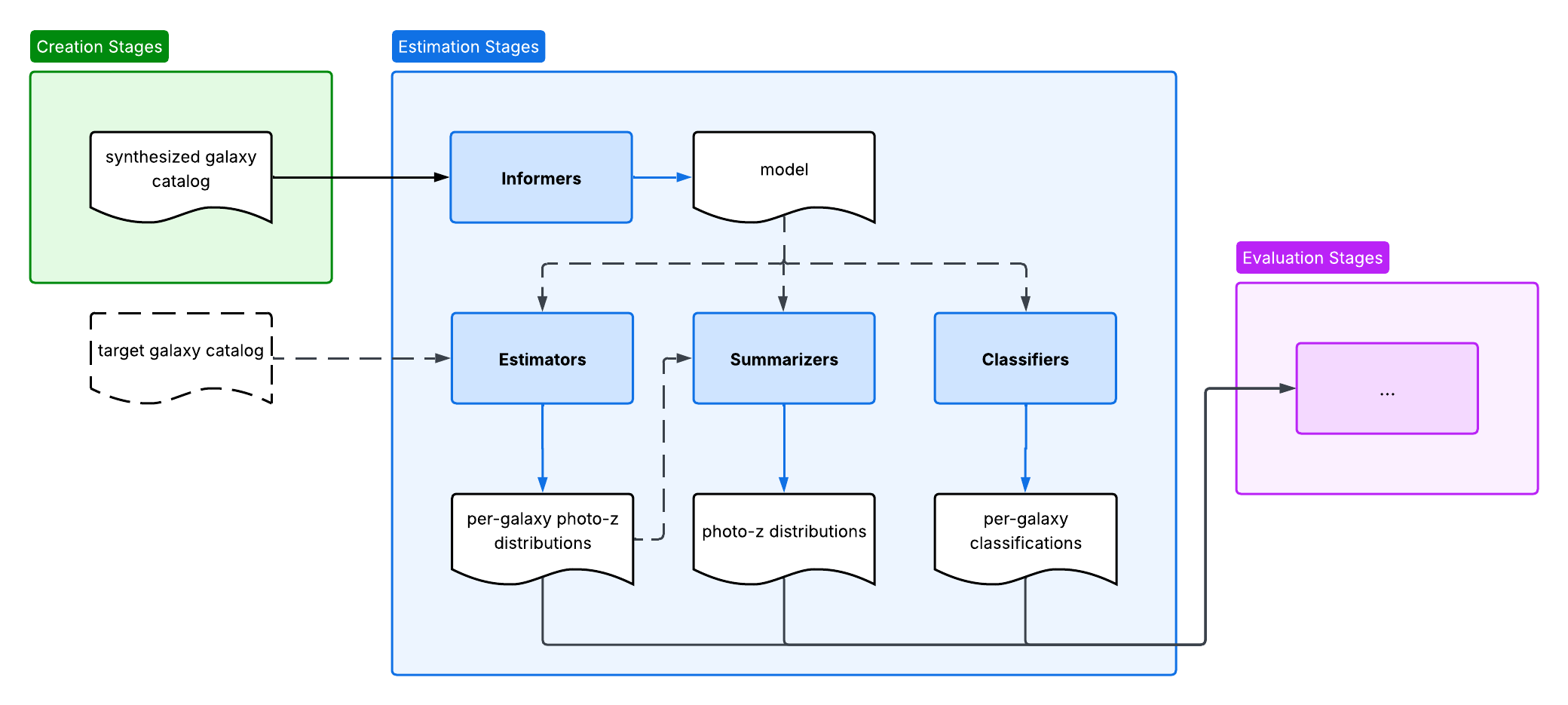
Estimators
rail.estimation encompasses all methods that derive redshift information from
photometry, as either an estimate of per-galaxy photo-z PDFs, a summary of the
redshift distribution \(n(z)\) for an ensemble of galaxies, or tomographic bin
assignments. Technically, information other than photometry can also be input to
the photo-z algorithms and is allowed in RAIL, especially for the machine
learning methods. Every such method is implemented with an Informer stage
paired with any combination of Estimator, Summarizer, and Classifier,
depending on which procedures are supported by the underlying estimator and
wrapped for RAIL.
An Estimator produces a qp.ensemble of per-galaxy photo-z PDFs, a
Summarizer produces a qp.ensemble of redshift distributions and/or samples
thereof, and a Classifier produces per-galaxy integer class IDs for
tomographic binning.
Informer generates a model for the Estimator, Summarizer, and Classifier
by the training data. Because ceci requires stages to have fixed numbers and
types of inputs, each of these stage types is implemented in at least one flavor
specifying what it takes as input; CatInformer and CatEstimator take as
input a photometric galaxy catalog with magnitudes; PZInformer,
PZClassifier, and PZSummarizer take as input a qp.ensemble of per-galaxy
photo-z PDFs; and SZPZSummarizer takes as input both a spectroscopic galaxy
catalog and a qp.ensemble of per-galaxy photo-z PDFs. Specific algorithms,
which are detailed below, are implemented as subclasses of these parent classes.
BPZ (Bayesian Photometric Redshifts)
RAIL Package: https://github.com/LSSTDESC/rail_bpz
BPZ is a template-based estimator developed by [Benitez et al
(2000)](https://ui.adsabs.harvard.edu/abs/2000ApJ…536..571B). Like many
template-based codes, it operates by computing synthetic fluxes for an input set
of SEDs by integrating the products of the SEDs and the filter bandpass curves
for a particular survey.
The BPZliteEstimator stage takes a TableHandle catalog of magnitudes and
magnitude errors as input, and returns an interpolated grid qp.Ensemble of
posterior PDFs. As the likelihood values are computed on a grid, the mode
values for each galaxy as measured on the grid are also returned by default.
Also included in the ancillary data are values tb corresponding to the
best-fit SED type (evaluated at the mode redshift), and todds, a parameter
that gives the fraction of the probability that comes from SED type tb at the
mode redshift. Low values of todds mean that multiple SEDs are contributing
to the probability total at the mode redshift, and thus a best fit type is
ill-defined, while values close to unity mean that most or all of the
probability is from a single SED type, and thus the use of a best fit type may
be appropriate for the individual galaxy.
- class rail.estimation.algos.bpz_lite.BPZliteInformer
Inform stage for BPZliteEstimator, this stage assumes that you have a set of SED templates and that the training data has already been assigned a ‘best fit broad type’ (that is, something like ellliptical, spiral, irregular, or starburst, similar to how the six SEDs in the CWW/SB set of Benitez (2000) are assigned 3 broad types). This informer will then fit parameters for the evolving type fraction as a function of apparent magnitude in a reference band, P(T|m), as well as the redshift prior of finding a galaxy of the broad type at a particular redshift, p(z|m, T) where z is redshift, m is apparent magnitude in the reference band, and T is the ‘broad type’. We will use the same forms for these functions as parameterized in Benitez (2000). For p(T|m) we have p(T|m) = exp(-kt(m-m0)) where m0 is a constant and we fit for values of kt For p(z|T,m) we have
` P(z|T,m) = f_x*z0_x^a *exp(-(z/zm_x)^a) where zm_x = z0_x*(km_x-m0) `where f_x is the type fraction from p(T|m), and we fit for values of z0, km, and a for each type. These parameters are then fed to the BPZ prior for use in the estimation stage.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
data_path ([str] default=None) – data_path (str): file path to the SED, FILTER, and AB directories. If left to default None it will use the install directory for rail + rail/examples_data/estimation_data/data
spectra_file ([str] default=CWWSB4.list) – name of the file specifying the list of SEDs to use
m0 ([float] default=20.0) – reference apparent mag, used in prior param
nt_array ([list] default=[1, 2, 5]) – list of integer number of templates per ‘broad type’, must be in same order as the template set, and must sum to the same number as the # of templates in the spectra file
mmin ([float] default=18.0) – lowest apparent mag in ref band, lower values ignored
mmax ([float] default=29.0) – highest apparent mag in ref band, higher values ignored
init_kt ([float] default=0.3) – initial guess for kt in training
init_zo ([float] default=0.4) – initial guess for z0 in training
init_alpha ([float] default=1.8) – initial guess for alpha in training
init_km ([float] default=0.1) – initial guess for km in training
type_file ([str] default=) – name of file with the broad type fits for the training data
output_hdfn ([bool] default=True) – if True, just return the default HDFN prior params rather than fitting
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Init function, init config stuff
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.bpz_lite.BPZliteEstimator
CatEstimator subclass to implement basic marginalized PDF for BPZ In addition to the marginalized redshift PDF, we also compute several ancillary quantities that will be stored in the ensemble ancil data: zmode: mode of the PDF amean: mean of the PDF tb: integer specifying the best-fit SED at the redshift mode todds: fraction of marginalized posterior prob. of best template, so lower numbers mean other templates could be better fits, likely at other redshifts
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
id_col ([str] default=object_id) – name of the object ID column
redshift_col (str] (default=redshift))
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
ref_band (str] (default=mag_i_lsst))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
dz ([float] default=0.01) – delta z in grid
unobserved_val ([float] default=-99.0) – value to be replaced with zero flux and given large errors for non-observed filters
data_path ([str] default=None) – data_path (str): file path to the SED, FILTER, and AB directories. If left to default None it will use the install directory for rail + ../examples_data/estimation_data/data
filter_list (list] (default=['DC2LSST_u', 'DC2LSST_g', 'DC2LSST_r', 'DC2LSST_i', 'DC2LSST_z', 'DC2LSST_y']))
spectra_file ([str] default=CWWSB4.list) – name of the file specifying the list of SEDs to use
madau_flag ([str] default=no) – set to ‘yes’ or ‘no’ to set whether to include intergalactic Madau reddening when constructing model fluxes
no_prior ([bool] default=False) – set to True if you want to run with no prior
p_min ([float] default=0.005) – BPZ sets all values of the PDF that are below p_min*peak_value to 0.0, p_min controls that fractional cutoff
gauss_kernel ([float] default=0.0) – gauss_kernel (float): BPZ convolves the PDF with a kernel if this is set to a non-zero number
zp_errors (list] (default=[0.1, 0.1, 0.1, 0.1, 0.1, 0.1]))
mag_err_min ([float] default=0.005) – a minimum floor for the magnitude errors to prevent a large chi^2 for very very bright objects
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor, build the CatEstimator, then do BPZ specific setup
- classmethod __new__(*args, **kwargs)
CMNN (Color-Matched Nearest Neighbor)
RAIL Package: https://github.com/LSSTDESC/rail_sklearn
CMNN, short for Color-Matched Nearest Neighbor, is a method introduced in
[Graham et al. (2018)](https://ui.adsabs.harvard.edu/abs/2018AJ….155….1G).
The algorithm identifies nearest neighbors based on the Mahalanobis distance in
color space from a set of galaxies with known spectroscopic redshifts with the
Mahalanobis distance.
Neighboring galaxies within a minimum Mahalanobis distance, defined via the percent point function (PPF), are retained, and there are several options from which a user can estimate a PDF from this subset: 1) a single galaxy from the subset is chosen at random from the subset; 2) a single galaxy is chosen, but with a probability weighted by the inverse of the square root of Mahalanobis distance; 3) the galaxy with the smallest Mahalanobis distance is chosen. In all three instances, the PDF for a galaxy is returned as a single Gaussian, where the central value is assigned to the spectroscopic redshift of the galaxy chosen from one of the three options listed above, and the uncertainty is calculated by computing the standard deviation of all galaxies in the minimum distance subset. When there are less than \(n_{\rm min}\) galaxies in the subset, the redshift will fail and an error flag is assigned to the galaxy.
- class rail.estimation.algos.cmnn.CMNNInformer
compute colors and color errors for CMNN training set and store in a model file that will be used by the CMNNEstimator stage
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
redshift_col (str] (default=redshift))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
nondetect_val (float] (default=99.0))
nondetect_replace ([bool] default=False) – set to True to replace non-detects, False to ignore in distance calculation
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor Do CatInformer specific initialization, then check on bands
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.cmnn.CMNNEstimator
Color Matched Nearest Neighbor Estimator Note that there are several modifications from the original CMNN, mainly that the original estimator dropped non-detections from the Mahalnobis distance calculation. However, there is information in a non-detection, so instead here I’ve replaced the non-detections with 1 sigma limit and a magnitude uncertainty of 1.0 and fixed the degrees of freedom to be the number of magnitude bands minus one.
Current implementation returns a single Gaussian for each galaxy with a width determined by the std deviation of all galaxies within the range set by the ppf value.
There are three options for how to choose the central value of the Gaussian and that option is set using the selection_mode config parameter (integer): option 0: randomly choose one of the neighbors within the PPF cutoff option 1: choose the value with the smallest Mahalnobis distance option 2: random choice as in option 0, but weighted by distance
If a test galaxy does not have enough training galaxies it is assigned a redshift bad_redshift_val and a width bad_redshift_err, both of which are config parameters that can be set by the user. Note that this should only happen if the number of training galaxies is smaller than min_n, which is unlikely, but is included here for completeness.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
id_col ([str] default=object_id) – name of the object ID column
redshift_col (str] (default=redshift))
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
seed ([int] default=66) – random seed used in selection mode
ppf_value ([float] default=0.68) – PPF value used in Mahalanobis distance
selection_mode ([int] default=1) – select which mode to choose the redshift estimate:0: randomly choose, 1: nearest neigh, 2: weighted random
min_n ([int] default=25) – minimum number of training galaxies to use
min_thresh ([float] default=0.0001) – minimum threshold cutoff
min_dist ([float] default=0.0001) – minimum Mahalanobis distance
bad_redshift_val ([float] default=99.0) – redshift to assign bad redshifts
bad_redshift_err ([float] default=10.0) – Gauss error width to assign to bad redshifts
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do Estimator specific initialization
- classmethod __new__(*args, **kwargs)
Delight
RAIL Package: https://github.com/LSSTDESC/rail_delight
Leistedt et al. (2017) introduced a novel approach to inferring photometric redshifts which combines some of the strengths of machine learning and template-fitting methods by implicitly constructing flexible template SEDs directly from the spectroscopic training data, called Delight. It is a method for calculating the posterior probability of redshift given a catalog of deep observations acting as a data-driven prior. The catalog can have observations in arbitrary bands and with arbitrary noise; Gaussian processes are used as a principled method to implicitly construct SEDs (capturing the effects of redshifts, bandpasses and noise). The hyperparameters of the Gaussian process can be optimized as a calibration step.
DNF (Directional Neighborhood Fitting)
RAIL Package: https://github.com/LSSTDESC/rail_dnf
DNF (Directional Neighborhood Fitting) is a photometric redshift estimation
method described by De Vicente et al.
(2016). The algorithm
estimates the photo-z of each galaxy from the hyperplane that best fits its
directional neighborhood in the training sample. DNF supports three main
distance metrics: ENF (Euclidean Neighborhood Fitting), ANF (Angular
Neighborhood Fitting), and a combination of both (DNF). ENF relies on the
Euclidean distance, making it a straightforward and commonly used approach in
k-Nearest Neighbors (kNN) methods. ANF uses a normalized inner product,
which provides the most accurate redshift predictions, particularly in data sets
with fluxes in more than four bands and sufficiently high signal-to-noise
ratios. Finally, DNF combines the Euclidean and angular metrics, improving
accuracy in cases of few bands and low signal-to-noise conditions.
DNF provides two photometric redshift estimates: DNF_Z, which is computed as
the weighted average or hyperplane fit of a set of neighbors determined by a
specific metric, and DNF_ZN, which corresponds to the redshift of the closest
neighbor and can be used for estimating the sample redshift distribution.
To construct the PDF for photometric redshifts, DNF selects a set of nearest
neighbors based on one of these distance metrics and assigns weights to them.
The PDF is computed by estimating the redshift distribution of the selected
neighbors and applying a Gaussian smoothing function to account for
uncertainties.
- class rail.estimation.algos.dnf.DNFInformer
A class for photometric redshift estimation.
This class extends CatInformer and processes photometric data to train for estimating redshifts. It handles missing data by replacing non-detections with predefined magnitude limits and assigns errors accordingly.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname (str] (default=photometry))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
redshift_col (str] (default=redshift))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
nondetect_val (float] (default=99.0))
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor Do CatInformer specific initialization, then check on bands
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.dnf.DNFEstimator
A class for estimating photometric redshifts using the DNF method.
This class extends CatEstimator and predicts redshifts based on photometric. It supports multiple selection modes for redshift estimation, processes missing data, and generates probability density functions (PDFs) for photometric redshifts.
Metrics (selection_mode): - ENF (1): Euclidean neighbourhood. It’s a common distance metric used in kNN (k-Nearest Neighbors) for photometric redshift prediction. - ANF (2): uses normalized inner product for more accurate photo-z predictions. It is particularly recommended when working with datasets containing more than four filters. - DNF (3): combines Euclidean and angular metrics, improving accuracy, especially for larger neighborhoods, and maintaining proportionality in observable content.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
id_col ([str] default=object_id) – name of the object ID column
redshift_col (str] (default=redshift))
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
selection_mode ([int] default=1) – select which mode to choose the redshift estimate:0: ENF, 1: ANF, 2: DNF
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do Estimator specific initialization
- classmethod __new__(*args, **kwargs)
FlexZBoost
RAIL Package: https://github.com/LSSTDESC/rail_flexzboost
FlexZBoost (Izbicki & Lee,
2017, Dalmasso et
al., 2020) is an
algorithm based on conditional density estimation that uses the FlexCode
package (available at
https://github.com/lee-group-cmu/FlexCode).
The package parameterizes the PDF as a linear combination of orthonormal basis
functions (a set of unit vectors in the color space that are orthogonal to each
other), where the basis function coefficients can be determined by regression.
The RAIL implementation uses xgboost (Chen & Guestrin,
2016) to perform the regression. The basis
function representation of the photo-z PDF of a galaxy can lead to small-scale
residual “bumps”. In the course of training the density estimate, an optimal
threshold (configuration parameter bump_thresh) below which small-scale
features are removed is determined by setting aside a fraction of the training
data and minimizing the CDE loss at different threshold values. Additionally,
the width of the final PDF is similarly optimized by the inclusion of a
“sharpening” parameter that scales the PDF by a power law value \(\alpha\). Again,
a fraction of the training data is set aside and the CDE loss is minimized over
a set of \(\alpha\) values. The resultant photo-z PDF distributions can be stored
as qp.Ensembles either in their native basis function representation or as a
linearly interpolated grid.
- class rail.estimation.algos.flexzboost.FlexZBoostInformer
Train a FlexZBoost CatInformer
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
retrain_full ([bool] default=True) – if True, re-run the fit with the full training set, including data set aside for bump/sharpen validation. If False, only use the subset defined via trainfrac fraction
trainfrac ([float] default=0.75) – fraction of training data to use for training (rest used for bump thresh and sharpening determination)
seed ([int] default=1138) – Random number seed
bumpmin ([float] default=0.02) – minimum value in grid of thresholds checked to optimize removal of spurious small bumps
bumpmax ([float] default=0.35) – max value in grid checked for removal of small bumps
nbump ([int] default=20) – number of grid points in bumpthresh grid search
sharpmin ([float] default=0.7) – min value in grid checked in optimal sharpening parameter fit
sharpmax ([float] default=2.1) – max value in grid checked in optimal sharpening parameter fit
nsharp ([int] default=15) – number of search points in sharpening fit
max_basis ([int] default=35) – maximum number of basis funcitons to use in density estimate
basis_system ([str] default=cosine) – type of basis sytem to use with flexcode
regression_params ([dict] default={'max_depth': 8, 'objective': 'reg:squarederror'}) – dictionary of options passed to flexcode, includes max_depth (int), and objective, which should be set to reg:squarederror
include_mag_err ([bool] default=False) – Include magnitude error in the training and estimationprocess
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor Do CatInformer specific initialization, then check on bands
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.flexzboost.FlexZBoostEstimator
FlexZBoost-based CatEstimator
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins (int] (default=301))
id_col ([str] default=object_id) – name of the object ID column
redshift_col ([str] default=redshift) – name of redshift column
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
ref_band (str] (default=mag_i_lsst))
qp_representation ([str] default=interp) – qp generator to use. [interp|flexzboost]
include_mag_err ([bool] default=False) – Include magnitude error in the training and estimationprocess
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do CatEstimator specific initialization
- classmethod __new__(*args, **kwargs)
GPz
RAIL Package: https://github.com/LSSTDESC/rail_gpz_v1
GPz is an algorithm based on sparse Gaussian Processes, introduced by
Almosallam et al. (2016). The current RAIL
implementation of GPz is a preliminary version; it predicts a single Gaussian
PDF rather than the more sophisticated multimodal PDFs implemented in newer
versions of GPz (Stylianou et al., 2022).
GPz models both the mean and standard deviation of the Gaussian PDF as a
linear combination of basis functions, learning the parameters for these basis
functions via a Gaussian process. The method can make several assumptions about
the covariance between these basis functions, controlled via the configuration
parameter gpz_method as outlined in the RAIL documentation.
- class rail.estimation.algos.gpz.GPzInformer
Inform stage for GPz_v1
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
trainfrac ([float] default=0.75) – fraction of training data used to make tree, rest used to set best sigma
seed ([int] default=87) – random seed
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
redshift_col (str] (default=redshift))
gpz_method ([str] default=VC) – method to be used in GPz, options are ‘GL’, ‘VL’, ‘GD’, ‘VD’, ‘GC’, and ‘VC’
n_basis ([int] default=50) – number of basis functions used
learn_jointly ([bool] default=True) – if True, jointly learns prior linear mean function
hetero_noise ([bool] default=True) – if True, learns heteroscedastic noise process, set False for point est.
csl_method ([str] default=normal) – cost sensitive learning type, ‘balanced’, ‘normalized’, or ‘normal’
csl_binwidth ([float] default=0.1) – width of bin for ‘balanced’ cost sensitive learning
pca_decorrelate ([bool] default=True) – if True, decorrelate data using PCA as preprocessing stage
max_iter ([int] default=200) – max number of iterations
max_attempt ([int] default=100) – max iterations if no progress on validation
log_errors ([bool] default=True) – if true, take log of magnitude errors
replace_error_vals (list] (default=[0.1, 0.1, 0.1, 0.1, 0.1, 0.1]))
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor Do CatInformer specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.gpz.GPzEstimator
Estimate stage for GPz_v1
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
id_col ([str] default=object_id) – name of the object ID column
redshift_col ([str] default=redshift) – name of redshift column
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
ref_band (str] (default=mag_i_lsst))
log_errors ([bool] default=True) – if true, take log of magnitude errors
replace_error_vals (list] (default=[0.1, 0.1, 0.1, 0.1, 0.1, 0.1]))
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do CatEstimator specific initialization
- classmethod __new__(*args, **kwargs)
k-Nearest Neighbor
RAIL Package: https://github.com/LSSTDESC/rail_sklearn
The nearest-neighbor code estimates redshift PDFs as a Gaussian mixture model,
where the number of Gaussians, M, is determined during the inform stage, as are
the width of the Gaussians. This is done by setting aside a fraction of the
training data as a validation set and minimizing the Conditional Density
Estimate (CDE) Loss of the PDFs versus the true values for that set.
KNearNeighInformer uses sklearn.neighbors.KDTree to build a tree from the
colors, or colors plus a reference band magnitude, of the training data.
KNearNeighEstimator then searches the tree for the M closest neighbors, and
constructs a PDF with M Gaussians centered at each of the corresponding
nearest neighbor redshifts.
- class rail.estimation.algos.k_nearneigh.KNearNeighInformer
Train a KNN-based estimator
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname (str] (default=photometry))
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
trainfrac ([float] default=0.75) – fraction of training data used to make tree, rest used to set best sigma
seed ([int] default=0) – Random number seed for NN training
sigma_grid_min ([float] default=0.01) – minimum value of sigma for grid check
sigma_grid_max ([float] default=0.075) – maximum value of sigma for grid check
ngrid_sigma ([int] default=10) – number of grid points in sigma check
leaf_size ([int] default=15) – min leaf size for KDTree
nneigh_min ([int] default=3) – int, min number of near neighbors to use for PDF fit
nneigh_max ([int] default=7) – int, max number of near neighbors to use ofr PDF fit
only_colors ([bool] default=False) – if only_colors True, then do not use ref_band mag, only use colors
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor Do CatInformer specific initialization, then check on bands
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.k_nearneigh.KNearNeighEstimator
KNN-based estimator
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
id_col ([str] default=object_id) – name of the object ID column
redshift_col (str] (default=redshift))
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
ref_band (str] (default=mag_i_lsst))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do Estimator specific initialization
- classmethod __new__(*args, **kwargs)
LePhare
RAIL Package: https://github.com/LSSTDESC/rail_lephare
We have implemented the LePHARE code within RAIL. LePHARE (Photometric Analysis for Redshift Estimation) is a template-fitting algorithm originally introduced by Arnouts et al. (1999) and further developed by Ilbert et al. (2006). It is written in C++ with a Python wrapper and is used to estimate redshift and physical property posteriors.
Within RAIL, we have integrated LePHARE with a default set of parameters optimized for LSST passbands. However, it remains fully customizable, consistent with the general LePHARE configuration parameters, which are extensive and well documented. These default configurations are based on those used for the COSMOS2020 data sets, as detailed in Weaver et al. (2022). The full set of values is available in the public version of the LePHARE code.
This implementation adds functionality such as the estimation of stellar mass, star-formation rate, and best-fitting model.
- class rail.estimation.algos.lephare.LephareInformer
Inform stage for LephareEstimator
This class will set templates and filters required for photoz estimation.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
lephare_config ([dict] (default={...})) – The lephare config keymap.
star_config ([dict] default={'LIB_ASCII': 'YES'}) – Star config overrides.
gal_config ([dict] default={'LIB_ASCII': 'YES', 'MOD_EXTINC': '18,26,26,33,26,33,26,33', 'EXTINC_LAW': 'SMC_prevot.dat,SB_calzetti.dat,SB_calzetti_bump1.dat,SB_calzetti_bump2.dat', 'EM_LINES': 'EMP_UV', 'EM_DISPERSION': '0.5,0.75,1.,1.5,2.'}) – Galaxy config overrides.
qso_config ([dict] default={'LIB_ASCII': 'YES', 'MOD_EXTINC': '0,1000', 'EB_V': '0.,0.1,0.2,0.3', 'EXTINC_LAW': 'SB_calzetti.dat'}) – QSO config overrides.
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Init function, init config stuff (COPIED from rail_bpz)
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.lephare.LephareEstimator
LePhare-base CatEstimator
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
id_col ([str] default=object_id) – name of the object ID column
redshift_col (str] (default=redshift))
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
ref_band (str] (default=mag_i_lsst))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
lephare_config ([dict] default={}) – The lephare config keymap. If unset we load it from the model.
use_inform_offsets ([bool] default=True) – Use the zero point offsets computed in the inform stage.
posterior_output ([int] default=11) – Which posterior distribution to output.MASS: 0SFR: 1SSFR: 2LDUST: 3LIR: 4AGE: 5COL1: 6COL2: 7MREF: 8MIN_ZG: 9MIN_ZQ: 10BAY_ZG: 11BAY_ZQ: 12
output_keys ([list] default=['Z_BEST', 'CHI_BEST', 'ZQ_BEST', 'CHI_QSO', 'MOD_STAR', 'CHI_STAR']) – The output keys to add to ancil. These must be in the output para file. By default we include the best galaxy and QSO redshift and best star alongside their respective chi squared.
run_dir ([str] default=None) – Override for the LEPHAREWORK directory. If None we load it from the model which is set during the inform stage. This is to facilitate manually moving intermediate files.
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Estimator
- classmethod __new__(*args, **kwargs)
Neural Network
RAIL Package: https://github.com/LSSTDESC/rail_sklearn
The neural network estimator is an unsophisticated implementation and is not
meant to be a competitive algorithm. Instead, it is used as a simple example
code and a baseline against which to test. This method constructs a model using
sklearn.neural_network.MLPRegressor to build a neural network trained on one
magnitude (set by the ref_band configuration parameter) and all of the colors
from the training data, though it first regularizes the data using
sklearn.preprocessing.StandardScaler.transform().
The network is set up using two hidden layers of size twelve, and a hyperbolic
tangent activation function. The estimation stage produces a Gaussian redshift
PDF by running the MLPRegressor’s predict() method to estimate the mean
redshift. A configuration parameter, width is used to set the width of the
Gaussian PDF, which is scaled by \((1+z)\) to increase with redshift, since the
uncertainty in wavelength, which directly translates to photo-z uncertainty,
scales with \((1+z)\).
- class rail.estimation.algos.sklearn_neurnet.SklNeurNetInformer
Subclass to train a simple point estimate Neural Net photoz rather than actually predict PDF, for now just predict point zb and then put an error of width*(1+zb). We’ll do a “real” NN photo-z later.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname (str] (default=photometry))
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
width ([float] default=0.05) – The ad hoc base width of the PDFs
max_iter ([int] default=500) – max number of iterations while training the neural net. Too low a value will cause an error to be printed (though the code will still work, justnot optimally)
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do CatInformer specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.sklearn_neurnet.SklNeurNetEstimator
Subclass to implement a simple point estimate Neural Net photoz rather than actually predict PDF, for now just predict point zb and then put an error of width*(1+zb). We’ll do a “real” NN photo-z later.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
id_col ([str] default=object_id) – name of the object ID column
redshift_col ([str] default=redshift) – name of redshift column
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
width ([float] default=0.05) – The ad hoc base width of the PDFs
ref_band (str] (default=mag_i_lsst))
nondetect_val (float] (default=99.0))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do CatEstimator specific initialization
- classmethod __new__(*args, **kwargs)
PZFlow
RAIL Package: https://github.com/LSSTDESC/rail_pzflow
PZFlow is a photometric redshift estimation algorithm that utilizes
normalizing flows. It takes a catalog of galaxy colors and redshifts and learns
a differentiable mapping from the data space to a simple latent space, such as a
Normal distribution. A photo-z posterior can then be estimated by evaluating
this probability over a grid of redshifts and normalizing the posterior to unit
probability. See Crenshaw et al. (2024) for
more details.
- class rail.estimation.algos.pzflow_nf.PZFlowInformer
Subclass to train a pzflow-based estimator
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – min z
zmax ([float] default=3.0) – max_z
nzbins ([int] default=301) – num z bins
flow_seed ([int] default=0) – seed for flow
ref_column_name ([str] default=mag_i_lsst) – name for reference column
column_names ([list] default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']) – column names to be used in flow
mag_limits ([dict] default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}) – 1 sigma mag limits
include_mag_errors ([bool] default=False) – Boolean flag on whether to marginalizeover mag errors (NOTE: much slower on CPU!)
error_names_dict ([dict] default={'mag_err_u_lsst': 'mag_u_lsst_err', 'mag_err_g_lsst': 'mag_g_lsst_err', 'mag_err_r_lsst': 'mag_r_lsst_err', 'mag_err_i_lsst': 'mag_i_lsst_err', 'mag_err_z_lsst': 'mag_z_lsst_err', 'mag_err_y_lsst': 'mag_y_lsst_err'}) – dictionary to rename error columns
n_error_samples ([int] default=1000) – umber of error samples in marginalization
soft_sharpness ([int] default=10) – sharpening paremeter for SoftPlus
soft_idx_col ([int] default=0) – index column for SoftPlus
redshift_column_name ([str] default=redshift) – name of redshift column
num_training_epochs ([int] default=50) – number flow training epochs
input (TableHandle (INPUT))
model (FlowHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor, build the CatInformer, then do PZFlow specific setup
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.pzflow_nf.PZFlowEstimator
CatEstimator which uses PZFlow
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid
zmax ([float] default=3.0) – The maximum redshift of the z grid
nzbins ([int] default=301) – The number of gridpoints in the z grid
id_col ([str] default=object_id) – name of the object ID column
redshift_col ([str] default=redshift) – name of redshift column
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
flow_seed ([int] default=0) – seed for flow
ref_column_name ([str] default=mag_i_lsst) – name for reference column
column_names ([list] default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']) – column names to be used in flow
mag_limits ([dict] default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}) – 1 sigma mag limits
include_mag_errors ([bool] default=False) – Boolean flag on whether to marginalizeover mag errors (NOTE: much slower on CPU!)
error_names_dict ([dict] default={'mag_err_u_lsst': 'mag_u_lsst_err', 'mag_err_g_lsst': 'mag_g_lsst_err', 'mag_err_r_lsst': 'mag_r_lsst_err', 'mag_err_i_lsst': 'mag_i_lsst_err', 'mag_err_z_lsst': 'mag_z_lsst_err', 'mag_err_y_lsst': 'mag_y_lsst_err'}) – dictionary to rename error columns
n_error_samples ([int] default=1000) – umber of error samples in marginalization
redshift_column_name ([str] default=redshift) – name of redshift column
model (FlowHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Estimator
- classmethod __new__(*args, **kwargs)
Random Gaussian
RAIL Package: https://github.com/LSSTDESC/rail_base
Benchmark algorithm.
- class rail.estimation.algos.random_gauss.RandomGaussInformer
Placeholder Informer
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Informer that can inform models for redshift estimation
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.random_gauss.RandomGaussEstimator
Random CatEstimator
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
id_col ([str] default=object_id) – name of the object ID column
redshift_col ([str] default=redshift) – name of redshift column
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
rand_width ([float] default=0.025) – ad hock width of PDF
seed ([int] default=87) – random seed
column_name ([str] default=mag_i_lsst) – name of a column that has the correct number of galaxies to find length of
input (TableHandle (INPUT))
model (ModelHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do CatEstimator specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
TPZ
RAIL Package: https://github.com/LSSTDESC/rail_tpz
TrainZ
RAIL Package: https://github.com/LSSTDESC/rail_base
Benchmark Algorithm.
- class rail.estimation.algos.train_z.TrainZInformer
Train an Estimator which returns a global PDF for all galaxies
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
redshift_col ([str] default=redshift) – name of redshift column
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Informer that can inform models for redshift estimation
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.train_z.TrainZEstimator
CatEstimator which returns a global PDF for all galaxies
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
id_col ([str] default=object_id) – name of the object ID column
redshift_col ([str] default=redshift) – name of redshift column
calc_summary_stats ([bool] default=False) – Compute summary statistics
calculated_point_estimates ([list] default=[]) – List of strings defining which point estimates to automatically calculate using qp.Ensemble.Options include, ‘mean’, ‘mode’, ‘median’.
recompute_point_estimates ([bool] default=False) – Force recomputation of point estimates
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Estimator
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Summarizers
The summarizers summarize the redshift distribution of an ensemble, whether based on photo-z or on other dataset such as spectroscopic redshift, or both. The calibration modules, which make adjustments globally to photo-z based on extra information from other datasets, usually reference samples of a spectroscopic survey, also are also among the summarizers.
Self Organizing Maps (minisom and somoclu)
RAIL Package: https://github.com/LSSTDESC/rail_som
rail_som contains two implementations of SOM-based calibration: minisom_som,
based on the light minimalistic SOM package
minisom, and somoclu_som using the
somoclu package.
somoclu is a parallelized package capable of constructing SOMs on large
datasets. It supports rectangular and hexagonal SOM cells, planar and toroidal
topologies, and random or principal component analysis initialization.
There is an option to further group the SOM cells into hierarchical clusters
using the AgglomerativeClustering class from the sklearn.cluster package.
This option adds flexibility and speed when grouping galaxies in the
magnitude/color space.
Minisom informer and estimator:
- class rail.estimation.algos.minisom_som.MiniSOMInformer
Summarizer that uses a SOM to construct a weighted sum of spec-z objects in the same SOM cell as each photometric galaxy in order to estimate the overall N(z). This is very related to the NZDir estimator, though that estimator actually reverses this process and looks for photometric neighbors around each spectroscopic galaxy, which can lead to problems if there are photometric galaxies with no nearby spec-z objects (NZDir is not aware that such objects exist and thus can hid biases). Part of the SimpeSOM estimator will be a check for cells which contain photometric objects but do not contain any corresponding training/spec-z objects, those unmatched objects will be flagged for possible removal from the input sample. The inform stage will simply construct a 2D grid SOM using minisom from a large sample of input photometric data and save this as an output. This may be a computationally intensive stage, though it will hopefully be run once and used by the estimate/summarize stage many times without needing to be re-run.
We can make the SOM either with all colors, or one magnitude and N colors, or an arbitrary set of columns. The code includes a flag column_usage to set usage, If set to “colors” it will take the difference of each adjacen pair of columns in bands as the colors. If set to magandcolors it will use these colors plus one magnitude as specified by ref_band. If set to columns then it will take as inputs all of the columns specified by bands (they can be magnitudes, colors, or any other input specified by the user). NOTE: any custom bands parameters must have an accompanying nondetect_val dictionary that will replace nondetections with the nondetect_val values!
This will make a pickle file containing the minisom SOM object that will be used by the estimation/summarization stage
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname (str] (default=photometry))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
ref_band (str] (default=mag_i_lsst))
column_usage ([str] default=magandcolors) – switch for how SOM uses columns, valid values are ‘colors’, ‘magandcolors’, and ‘columns’
seed ([int] default=0) – Random number seed
m_dim ([int] default=31) – number of cells in SOM y dimension
n_dim ([int] default=31) – number of cells in SOM x dimension
som_sigma ([float] default=1.5) – sigma param in SOM training
som_learning_rate ([float] default=0.5) – SOM learning rate
som_iterations ([int] default=10000) – number of iterations in SOM training
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do Informer specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.minisom_som.MiniSOMSummarizer
Quick implementation of a SOM-based summarizer that constructs and N(z) estimate via a weighted sum of the empirical N(z) consisting of the normalized histogram of spec-z values contained in the same SOM cell as each photometric galaxy. There are some general guidelines to choosing the geometry and number of total cells in the SOM. This paper: http://www.giscience2010.org/pdfs/paper_230.pdf recommends 5*sqrt(num rows * num data columns) as a rough guideline. Some authors state that a SOM with one dimension roughly twice as long as the other are better, while others find that square SOMs with equal X and Y dimensions are best, the user can set the dimensions using the n_dim and m_dim parameters. For more discussion on SOMs and photo-z calibration, see the KiDS paper on the topic: http://arxiv.org/abs/1909.09632 particularly the appendices. Note that several parameters are stored in the model file, e.g. the columns used. This ensures that the same columns used in constructing the SOM are used when finding the winning SOM cell with the test data. Two additional files are also written out: cellid_output outputs the ‘winning’ SOM cell for each photometric galaxy, in both raveled and 2D SOM cell coordinates. If the objectID or galaxy_id is present they will also be included in this file, if not the coordinates will be written in the same order in which the data is read in. uncovered_cell_file outputs the raveled cell IDs of cells that contain photometric galaxies but no corresponding spectroscopic objects, these objects should be removed from the sample as they cannot be accounted for properly in the summarizer. Some iteration on data cuts may be necessary to remove/mitigate these ‘uncovered’ objects.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
hdf5_groupname (str] (default=photometry))
redshift_col (str] (default=redshift))
objid_name ([str] default=) – A parameter
spec_groupname ([str] default=photometry) – name of hdf5 group for spec data, if None, then set to ‘’
seed ([int] default=12345) – random seed
phot_weightcol ([str] default=) – name of photometry weight, if present
spec_weightcol ([str] default=) – name of specz weight col, if present
nsamples ([int] default=20) – number of bootstrap samples to generate
input (TableHandle (INPUT))
spec_input (TableHandle (INPUT))
model (ModelHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
cellid_output (TableHandle (OUTPUT))
uncovered_cell_file (TableHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Estimator that can sample galaxy data.
- classmethod __new__(*args, **kwargs)
Somoclu informer and estimator:
- class rail.estimation.algos.somoclu_som.SOMocluInformer
Summarizer that uses a SOM to construct a weighted sum of spec-z objects in the same SOM cell as each photometric galaxy in order to estimate the overall N(z). This is very related to the NZDir estimator, though that estimator actually reverses this process and looks for photometric neighbors around each spectroscopic galaxy, which can lead to problems if there are photometric galaxies with no nearby spec-z objects (NZDir is not aware that such objects exist and thus can hid biases).
We apply somoclu package (https://somoclu.readthedocs.io/) to train the SOM.
Part of the SOM estimator will be a check for cells which contain photometric objects but do not contain any corresponding training/spec-z objects, those unmatched objects will be flagged for possible removal from the input sample. The inform stage will simply construct a 2D grid SOM using somoclu from a large sample of input photometric data and save this as an output. This may be a computationally intensive stage, though it will hopefully be run once and used by the estimate/summarize stage many times without needing to be re-run.
We can make the SOM either with all colors, or one magnitude and N colors, or an arbitrary set of columns. The code includes a flag column_usage to set usage, If set to “colors” it will take the difference of each adjacen pair of columns in bands as the colors. If set to magandcolors it will use these colors plus one magnitude as specified by ref_band. If set to columns then it will take as inputs all of the columns specified by bands (they can be magnitudes, colors, or any other input specified by the user). NOTE: any custom bands parameters must have an accompanying nondetect_val dictionary that will replace nondetections with the nondetect_val values!
This creates a pickle file containing the somoclu SOM object that will be used by the estimation/summarization stage
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname (str] (default=photometry))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
bands (list] (default=['mag_u_lsst', 'mag_g_lsst', 'mag_r_lsst', 'mag_i_lsst', 'mag_z_lsst', 'mag_y_lsst']))
err_bands (list] (default=['mag_err_u_lsst', 'mag_err_g_lsst', 'mag_err_r_lsst', 'mag_err_i_lsst', 'mag_err_z_lsst', 'mag_err_y_lsst']))
ref_band (str] (default=mag_i_lsst))
redshift_col (str] (default=redshift))
column_usage ([str] default=magandcolors) – switch for how SOM uses columns, valid values are ‘colors’,’magandcolors’, and ‘mags’
seed ([int] default=0) – Random number seed
n_rows ([int] default=31) – number of cells in SOM y dimension
n_columns ([int] default=31) – number of cells in SOM x dimension
gridtype ([str] default=rectangular) – Optional parameter to specify the grid form of the nodes:* ‘rectangular’: rectangular neurons (default)* ‘hexagonal’: hexagonal neurons
n_epochs ([int] default=10) – number of training epochs.
initialization ([str] default=pca) – method of initializing the SOM:* ‘pca’: principal componant analysis (default)* ‘random’ randomly initialize the SOM
maptype ([str] default=planar) – Optional parameter to specify the map topology:* ‘planar’: Planar map (default)* ‘toroid’: Toroid map
std_coeff ([float] default=1.5) – Optional parameter to set the coefficient in the Gaussianneighborhood function exp(-||x-y||^2/(2*(coeff*radius)^2))Default: 1.5
som_learning_rate ([float] default=0.5) – Initial SOM learning rate (scale0 param in Somoclu)
input (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do Informer specific initialization
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.somoclu_som.SOMocluSummarizer
Quick implementation of a SOM-based summarizer. It will group a pre-trained SOM into hierarchical clusters and assign a galaxy sample into SOM cells and clusters. Then it constructs an N(z) estimation via a weighted sum of the empirical N(z) consisting of the normalized histogram of spec-z values contained in the same SOM cluster as each photometric galaxy. There are some general guidelines to choosing the geometry and number of total cells in the SOM. This paper: http://www.giscience2010.org/pdfs/paper_230.pdf recommends 5*sqrt(num rows * num data columns) as a rough guideline. Some authors state that a SOM with one dimension roughly twice as long as the other are better, while others find that square SOMs with equal X and Y dimensions are best, the user can set the dimensions using the n_columns and n_rows parameters. For more discussion on SOMs and photo-z calibration, see the KiDS paper on the topic: http://arxiv.org/abs/1909.09632 particularly the appendices. Note that several parameters are stored in the model file, e.g. the columns used. This ensures that the same columns used in constructing the SOM are used when finding the winning SOM cell with the test data. Two additional files are also written out: cellid_output outputs the ‘winning’ SOM cell for each photometric galaxy, in both raveled and 2D SOM cell coordinates. If the objectID or galaxy_id is present they will also be included in this file, if not the coordinates will be written in the same order in which the data is read in. uncovered_cell_file outputs the raveled cell IDs of cells that contain photometric galaxies but no corresponding spectroscopic objects, these objects should be removed from the sample as they cannot be accounted for properly in the summarizer. Some iteration on data cuts may be necessary to remove/mitigate these ‘uncovered’ objects.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin (float] (default=0.0))
zmax (float] (default=3.0))
nzbins (int] (default=301))
nondetect_val (float] (default=99.0))
mag_limits (dict] (default={'mag_u_lsst': 27.79, 'mag_g_lsst': 29.04, 'mag_r_lsst': 29.06, 'mag_i_lsst': 28.62, 'mag_z_lsst': 27.98, 'mag_y_lsst': 27.05}))
hdf5_groupname (str] (default=photometry))
redshift_col (str] (default=redshift))
spec_groupname ([str] default=photometry) – name of hdf5 group for spec data, if None, then set to ‘’
n_clusters ([int] default=-1) – The number of hierarchical clusters of SOM cells. If not provided, the SOM cells will not be clustered.
objid_name ([str] default=) – A parameter
seed ([int] default=12345) – random seed
redshift_colname ([str] default=redshift) – name of redshift column in specz file
phot_weightcol ([str] default=) – name of photometry weight, if present
spec_weightcol ([str] default=) – name of specz weight col, if present
split ([int] default=200) – the size of data chunks when calculating the distances between the codebook and data
nsamples ([int] default=20) – number of bootstrap samples to generate
useful_clusters ([list] default=[]) – the cluster indices that are used for calibration. If not given, then all the clusters containing spec sample are used.
input (TableHandle (INPUT))
spec_input (TableHandle (INPUT))
model (ModelHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
cellid_output (Hdf5Handle (OUTPUT))
uncovered_cluster_file (TableHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Estimator that can sample galaxy data.
- classmethod __new__(*args, **kwargs)
Useful function for the SOMoclu (see SOM tutorial for example):
- somoclu_som.get_bmus(data, split=200)
This function gets the “best matching unit (bmu)” of a given data on a pre-trained SOM. It works by multiprocessing chunks of the data. Input: som: a pre-trained Somoclu object; data: np.ndarray of the data vector. split: an integer specifying the size of data chunks when calculating the distances between the codebook and data;
- somoclu_som.plot_som(som_map, grid_type='rectangular', colormap=<matplotlib.colors.ListedColormap object>, cbar_name=None, vmin=None, vmax=None)
This function plots the pre-trained SOM. Input: ax: the axis to be plotted on. som_map: a 2-D array contains the value in a pre-trained SOM. The value can be the number of sources in each cell; or the mean feature in every cell. grid_type: string, either ‘rectangular’ or ‘hexagonal’. colormap: the colormap to show the values. default: cm.viridis. cbar_name: the label on the color bar.
Yet Another Wizz
RAIL Package: https://github.com/LSSTDESC/rail_yaw
The method proposed in Schmidt et al.
(2013) — measuring the
correlation functions between pairs of photometric samples and reference samples
in a single bin of radial distance between the two samples at a fixed physical
scale — is implemented in
yet_another_wizz (YAW; van den
Busch et al., 2020).
We provide a wrapper in cc_yaw.
This wrapper consists of a number of stages that interface with all primary YAW functionality:
YawCacheCreate: Data preparation — splitting input data samples into regions for spatial resampling and covariance estimation.YawAutoCorrelate: Measurement of the angular autocorrelation function amplitude to estimate the evolution of galaxy bias with redshift.YawCrossCorrelate: Measurement of the angular cross-correlation amplitude.YawSummarize: Estimation of the ensemble redshift distribution according to Eq.~(X) (as referenced in the original context).
- class rail.estimation.algos.cc_yaw.YawCacheCreate
Create a new cache directory to hold a data set and optionally its matching random catalog.
Both input data sets are split into consistent spatial patches that are required by yet_another_wizz for correlation function covariance estimates. Each patch is stored separately for efficient access.
The cache can be constructed from input files or tabular data in memory. Column names for sky coordinates are required, redshifts and per-object weights are optional. One out of three patch create methods must be specified:
Splitting the data into predefined patches (from ASCII file or an existing cache instance, linked as optional stage input).
Splitting the data based on a column with patch indices.
Generating approximately equal size patches using k-means clustering of objects positions (preferably randoms if provided).
Note: The cache directory must be deleted manually when it is no longer needed. (The reference sample cache may be reused when operating on tomographic bins.)
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
path ([str] (required)) – path to cache directory, must not exist
overwrite ([bool] default=None) – overwrite the path if it is an existing cache directory
ra_name ([str] default=ra) – column name of right ascension (in degrees)
dec_name ([str] default=dec) – column name of declination (in degrees)
weight_name ([str] default=None) – column name of weight
redshift_name ([str] default=None) – column name of redshift
degrees ([bool] default=True) – Whether the input coordinates are in degrees or radian.
patch_file ([str] default=None) – path to ASCII file that lists patch centers (one per line) as pair of R.A./Dec. in radian, separated by a single space or tab
patch_name ([str] default=None) – column name of patch index (starting from 0)
patch_num ([int] default=None) – number of spatial patches to create using knn on coordinates of randoms
probe_size ([int] default=-1) – The approximate number of objects to sample from the input file when generating patch centers.
max_workers ([int] default=None) – configure a custom maximum number of parallel workers to use
verbose ([str] default=info) – lowest log level emitted by yet_another_wizz
data (TableHandle (INPUT))
rand (TableHandle (INPUT))
patch_source (YawCacheHandle (INPUT))
output (YawCacheHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.cc_yaw.YawAutoCorrelate
Wrapper stage for yaw.autocorrelate to compute a sample’s angular autocorrelation amplitude.
Generally used for the reference sample to compute an estimate for its galaxy sample as a function of redshift. Data is provided as a single cache directory that must have redshifts and randoms with redshift attached.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
rmin ([float] (required)) – Single or sequence of lower scale limits in given ‘unit’.
rmax ([float] (required)) – Single or sequence of upper scale limits in given ‘unit’.
unit ([str] default=kpc) – The unit of the lower and upper scale limits.
rweight ([float] default=None) – Power-law exponent used to weight pairs by their separation.
resolution ([int] default=None) – Number of radial logarithmic bin used to approximate the weighting by separation.
zmin ([float] default=None) – Lowest redshift bin edge to generate (alternatively use ‘edges’).
zmax ([float] default=None) – Highest redshift bin edge to generate (alternatively use ‘edges’).
num_bins ([int] default=30) – Number of redshift bins to generate between ‘zmin’ and ‘zmax’.
method ([str] default=linear) – Method used to compute the spacing of bin edges.
edges ([float] default=None) – Use these custom bin edges instead of generating them.
closed ([str] default=right) – String indicating the side of the bin intervals that are closed.
max_workers ([int] default=None) – configure a custom maximum number of parallel workers to use
verbose ([str] default=info) – lowest log level emitted by yet_another_wizz
sample (YawCacheHandle (INPUT))
output (YawCorrFuncHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.cc_yaw.YawCrossCorrelate
Wrapper stage for yaw.crosscorrelate to compute the angular cross- correlation amplitude between the reference and the unknown sample.
Generally used for the reference sample to compute an estimate for its galaxy sample as a function of redshift. Data sets are provided as cache directories. The reference sample must have redshifts and at least one cache must have randoms attached.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
rmin ([float] (required)) – Single or sequence of lower scale limits in given ‘unit’.
rmax ([float] (required)) – Single or sequence of upper scale limits in given ‘unit’.
unit ([str] default=kpc) – The unit of the lower and upper scale limits.
rweight ([float] default=None) – Power-law exponent used to weight pairs by their separation.
resolution ([int] default=None) – Number of radial logarithmic bin used to approximate the weighting by separation.
zmin ([float] default=None) – Lowest redshift bin edge to generate (alternatively use ‘edges’).
zmax ([float] default=None) – Highest redshift bin edge to generate (alternatively use ‘edges’).
num_bins ([int] default=30) – Number of redshift bins to generate between ‘zmin’ and ‘zmax’.
method ([str] default=linear) – Method used to compute the spacing of bin edges.
edges ([float] default=None) – Use these custom bin edges instead of generating them.
closed ([str] default=right) – String indicating the side of the bin intervals that are closed.
max_workers ([int] default=None) – configure a custom maximum number of parallel workers to use
verbose ([str] default=info) – lowest log level emitted by yet_another_wizz
reference (YawCacheHandle (INPUT))
unknown (YawCacheHandle (INPUT))
output (YawCorrFuncHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.cc_yaw.YawSummarize
A summarizer that computes a clustering redshift estimate from the measured correlation amplitudes.
Evaluates the cross-correlation pair counts with the provided estimator. Additionally corrects for galaxy sample bias if autocorrelation measurements are provided as stage inputs.
Note: This summarizer does not produce a PDF, but a ratio of correlation functions, which may result in negative values. Further modelling of the output is required.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
verbose ([str] default=info) – lowest log level emitted by yet_another_wizz
cross_corr (YawCorrFuncHandle (INPUT))
auto_corr_ref (YawCorrFuncHandle (INPUT))
auto_corr_unk (YawCorrFuncHandle (INPUT))
output (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Naive Stacking
RAIL Package: https://github.com/LSSTDESC/rail_base
Stack the PDF of the photo-z output and normalize as the n(z) distribution.
- class rail.estimation.algos.naive_stack.NaiveStackInformer
Placeholder Informer
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
input (QPHandle (INPUT))
truth (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Informer that can inform models for redshift estimation
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.naive_stack.NaiveStackSummarizer
Summarizer which stacks individual P(z)
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
seed ([int] default=87) – random seed
n_samples ([int] default=1000) – Number of sample distributions to create
input (QPHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.naive_stack.NaiveStackMaskedSummarizer
Stage NaiveStackMaskedSummarizer
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
seed ([int] default=87) – random seed
n_samples ([int] default=1000) – Number of sample distributions to create
selected_bin ([int] default=-1) – bin to use
input (QPHandle (INPUT))
tomography_bins (TableHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Variational Inference Stacking
RAIL Package: https://github.com/LSSTDESC/rail_base
- class rail.estimation.algos.var_inf.VarInfStackInformer
Placeholder Informer
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
input (QPHandle (INPUT))
truth (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Informer that can inform models for redshift estimation
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.var_inf.VarInfStackSummarizer
Variational inference summarizer based on notebook created by Markus Rau The summzarizer is appropriate for the likelihoods returned by template-based codes, for which the NaiveSummarizer are not appropriate.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
seed ([int] default=87) – random seed
n_iter ([int] default=100) – The number of iterations in the variational inference
n_samples ([int] default=500) – The number of samples used in dirichlet uncertainty
input (QPHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Point Estimate Histogram
RAIL Package: https://github.com/LSSTDESC/rail_base
Use the point estimate histogram as n(z), baseline method.
- class rail.estimation.algos.point_est_hist.PointEstHistInformer
Placeholder Informer
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
input (QPHandle (INPUT))
truth (TableHandle (INPUT))
model (ModelHandle (OUTPUT))
- __init__(args, **kwargs)
Initialize Informer that can inform models for redshift estimation
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.point_est_hist.PointEstHistSummarizer
Summarizer which simply histograms a point estimate
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
seed ([int] default=87) – random seed
point_estimate_key ([str] default=zmode) – Which point estimate to use
n_samples ([int] default=1000) – Number of sample distributions to return
input (QPHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
- class rail.estimation.algos.point_est_hist.PointEstHistMaskedSummarizer
Summarizer which simply histograms a point estimate
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
nzbins ([int] default=301) – The number of gridpoints in the z grid
seed ([int] default=87) – random seed
point_estimate_key ([str] default=zmode) – Which point estimate to use
n_samples ([int] default=1000) – Number of sample distributions to return
selected_bin ([int] default=-1) – bin to use
input (QPHandle (INPUT))
tomography_bins (TableHandle (INPUT))
output (QPHandle (OUTPUT))
single_NZ (QPHandle (OUTPUT))
- __init__(args, **kwargs)
Constructor: Do RailStage specific initialization
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Classifiers
Classifiers assign classes to catalog-like tables. Classifier uses a generic “model”, the details of which depends on the sub-class. The model inputs either a table or qp ensemble, and outputs tabular data which can be appended to the estimation catalog.
Equal Count
RAIL Package: https://github.com/LSSTDESC/rail_base
Assign tomographic bins based on a point estimate according to SRD.
- class rail.estimation.algos.equal_count.EqualCountClassifier
Classifier that simply assign tomographic bins based on point estimate according to SRD
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
object_id_col ([str] default=) – name of object id column
point_estimate_key ([str] default=zmode) – Which point estimate to use
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
n_tom_bins ([int] default=5) – Number of tomographic bins
no_assign ([int] default=-99) – Value for no assignment flag
input (QPHandle (INPUT))
output (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
Initialize the PZClassifier.
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Uniform Binning
RAIL Package: https://github.com/LSSTDESC/rail_base
Assign tomographic bins based on a point estimate according to SRD.
- class rail.estimation.algos.uniform_binning.UniformBinningClassifier
Classifier that simply assigns tomographic bins based on a point estimate according to SRD.
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
object_id_col ([str] default=) – name of object id column
point_estimate_key ([str] default=zmode) – Which point estimate to use
zbin_edges ([list] default=[]) – The tomographic redshift bin edges.If this is given (contains two or more entries), all settings below will be ignored.
zmin ([float] default=0.0) – The minimum redshift of the z grid or sample
zmax ([float] default=3.0) – The maximum redshift of the z grid or sample
n_tom_bins ([int] default=5) – Number of tomographic bins
no_assign ([int] default=-99) – Value for no assignment flag
input (QPHandle (INPUT))
output (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
Initialize the PZClassifier.
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)
Random Forest
RAIL Package: https://github.com/LSSTDESC/rail_sklearn
Assign tomographic bins based on the random forest method.
- class rail.estimation.algos.random_forest.RandomForestClassifier
Classifier that assigns tomographic bins based on random forest method
- Parameters:
output_mode ([str] default=default) – What to do with the outputs. The options are ‘default’, where outputs will be written to files and some returned, and ‘return’, where outputs will only be returned and not written.
chunk_size ([int] default=10000) – Number of objects per chunk for parallel processing or to evalute per loop in single node processing
hdf5_groupname ([str] default=photometry) – name of hdf5 group for data, if None, then set to ‘’
id_name ([str] default=) – Column name for the object ID in the input data, if empty the row index is used as the ID.
class_bands ([list] default=['r', 'i', 'z']) – Which bands to use for classification
bands ([dict] default={'r': 'mag_r_lsst', 'i': 'mag_i_lsst', 'z': 'mag_z_lsst'}) – column names for the the bands
model (ModelHandle (INPUT))
input (TableHandle (INPUT))
output (Hdf5Handle (OUTPUT))
- __init__(args, **kwargs)
Initialize Classifier
- Parameters:
args (Any)
kwargs (Any)
- Return type:
None
- classmethod __new__(*args, **kwargs)