Clustering redshifts with yet_another_wizz
This notebooks summarises the steps to compute clustering redshifts for an unknown sample of galaxies using a reference sample with known redshifts. Additionally, a correction for the galaxy bias of the reference sample is applied (see Eqs. 17 & 20 in van den Busch et al. 2020).
This involves a number of steps (see schema below): 1. Preparing the input data (creating randoms, applying masks; simplfied here). 2. Splitting the data into spatial patches and cache them on disk for faster access. 3. Computing the autocorrelation function amplitude \(w_{\rm ss}(z)\), used as correction for the galaxy bias 4. Computing the cross-correlation function amplitude \(w_{\rm sp}(z)\), which is the biased redshift estimate. 5. Summarising the result by correcting for the refernece sample bias and producing a redshift estimate (not a PDF!).
Note: The cached data must be removed manually since its lifetime can currently not be handled by RAIL.
The aim of this notebook is to give an overview of the wrapper functionality, including a summary of all currently implemented optional parameters (commented). It is not meant to be a demonstaration of the performance of yet_another_wizz since the example data used here is very small and the resulting signal-to-noise ratio is quite poor.
Note: If you’re interested in running this in pipeline mode, see
10_YAW.ipynb
in the pipeline_examples/estimation_examples/ folder.
import shutil
from pathlib import Path
import matplotlib.pyplot as plt
from rail.core.data import Hdf5Handle
from rail.estimation.algos.cc_yaw import create_yaw_cache_alias
from rail.yaw_rail.utils import get_dc2_test_data
from yaw.randoms import BoxRandoms
from rail import interactive as ri
DOWNLOADS_DIR = Path("../examples_data")
DOWNLOADS_DIR.mkdir(exist_ok=True)
CACHE_DIR = DOWNLOADS_DIR / "yaw_cache"
CACHE_DIR.mkdir(exist_ok=True)
Install FSPS with the following commands:
pip uninstall fsps
git clone --recursive https://github.com/dfm/python-fsps.git
cd python-fsps
python -m pip install .
export SPS_HOME=$(pwd)/src/fsps/libfsps
LEPHAREDIR is being set to the default cache directory:
/home/runner/.cache/lephare/data
More than 1Gb may be written there.
LEPHAREWORK is being set to the default cache directory:
/home/runner/.cache/lephare/work
Default work cache is already linked.
This is linked to the run directory:
/home/runner/.cache/lephare/runs/20260504T123336
A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.2.6 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.
If you are a user of the module, the easiest solution will be to
downgrade to 'numpy<2' or try to upgrade the affected module.
We expect that some modules will need time to support NumPy 2.
Traceback (most recent call last): File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/runpy.py", line 86, in _run_code
exec(code, run_globals)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel_launcher.py", line 18, in <module>
app.launch_new_instance()
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/traitlets/config/application.py", line 1075, in launch_instance
app.start()
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/kernelapp.py", line 758, in start
self.io_loop.start()
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/tornado/platform/asyncio.py", line 211, in start
self.asyncio_loop.run_forever()
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/asyncio/base_events.py", line 603, in run_forever
self._run_once()
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/asyncio/base_events.py", line 1909, in _run_once
handle._run()
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/asyncio/events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/utils.py", line 71, in preserve_context
return await f(*args, **kwargs)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/kernelbase.py", line 621, in shell_main
await self.dispatch_shell(msg, subshell_id=subshell_id)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/kernelbase.py", line 478, in dispatch_shell
await result
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/ipkernel.py", line 372, in execute_request
await super().execute_request(stream, ident, parent)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/kernelbase.py", line 834, in execute_request
reply_content = await reply_content
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/ipkernel.py", line 464, in do_execute
res = shell.run_cell(
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/ipykernel/zmqshell.py", line 663, in run_cell
return super().run_cell(*args, **kwargs)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3077, in run_cell
result = self._run_cell(
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3132, in _run_cell
result = runner(coro)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/IPython/core/async_helpers.py", line 128, in _pseudo_sync_runner
coro.send(None)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3336, in run_cell_async
has_raised = await self.run_ast_nodes(code_ast.body, cell_name,
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3519, in run_ast_nodes
if await self.run_code(code, result, async_=asy):
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3579, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "/tmp/ipykernel_5366/2253991977.py", line 10, in <module>
from rail import interactive as ri
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/interactive/__init__.py", line 3, in <module>
from . import calib, creation, estimation, evaluation, tools
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/interactive/calib/__init__.py", line 3, in <module>
from rail.utils.interactive.initialize_utils import _initialize_interactive_module
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/utils/interactive/initialize_utils.py", line 17, in <module>
from rail.utils.interactive.base_utils import (
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/utils/interactive/base_utils.py", line 10, in <module>
rail.stages.import_and_attach_all(silent=True)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/stages/__init__.py", line 74, in import_and_attach_all
RailEnv.import_all_packages(silent=silent)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/core/introspection.py", line 541, in import_all_packages
_imported_module = importlib.import_module(pkg)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/som/__init__.py", line 1, in <module>
from rail.creation.degraders.specz_som import *
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/rail/creation/degraders/specz_som.py", line 15, in <module>
from somoclu import Somoclu
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/somoclu/__init__.py", line 11, in <module>
from .train import Somoclu
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/somoclu/train.py", line 25, in <module>
from .somoclu_wrap import train as wrap_train
File "/opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/somoclu/somoclu_wrap.py", line 11, in <module>
import _somoclu_wrap
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
File /opt/hostedtoolcache/Python/3.10.20/x64/lib/python3.10/site-packages/numpy/core/_multiarray_umath.py:44, in __getattr__(attr_name)
39 # Also print the message (with traceback). This is because old versions
40 # of NumPy unfortunately set up the import to replace (and hide) the
41 # error. The traceback shouldn't be needed, but e.g. pytest plugins
42 # seem to swallow it and we should be failing anyway...
43 sys.stderr.write(msg + tb_msg)
---> 44 raise ImportError(msg)
46 ret = getattr(_multiarray_umath, attr_name, None)
47 if ret is None:
ImportError:
A module that was compiled using NumPy 1.x cannot be run in
NumPy 2.2.6 as it may crash. To support both 1.x and 2.x
versions of NumPy, modules must be compiled with NumPy 2.0.
Some module may need to rebuild instead e.g. with 'pybind11>=2.12'.
If you are a user of the module, the easiest solution will be to
downgrade to 'numpy<2' or try to upgrade the affected module.
We expect that some modules will need time to support NumPy 2.
Warning: the binary library cannot be imported. You cannot train maps, but you can load and analyze ones that you have already saved.
The problem occurs because either compilation failed when you installed Somoclu or a path is missing from the dependencies when you are trying to import it. Please refer to the documentation to see your options.
VERBOSE = "debug" # verbosity level of built-in logger, disable with "error"
1. Data preparation
Since this is a simple example, we are not going into the details of creating realistic randoms and properly masking the reference and unknown data to a shared footprint on sky. Instead, we are using a simulated dataset that serves as both, reference and unknown sample.
First, we download the small test dataset derived from 25 sqdeg of DC2, containing 100k objects on a limited redshift range of \(0.2 < z < 1.8\). We add the data as new handle to the datastore.
test_data = get_dc2_test_data() # downloads test data, cached for future calls
redshifts = test_data["z"].to_numpy()
zmin = redshifts.min()
zmax = redshifts.max()
n_data = len(test_data)
print(f"N={n_data}, {zmin:.1f}<z<{zmax:.1f}")
handle_test_data = Hdf5Handle("input_data", test_data)
N=100000, 0.2<z<1.8
Next we generate a x10 enhanced uniform random dataset for the test data
constrained to its rectangular footprint. We add redshifts by cloning
the redshift column "z" of the dataset.
generator = BoxRandoms(
test_data["ra"].min(),
test_data["ra"].max(),
test_data["dec"].min(),
test_data["dec"].max(),
redshifts=redshifts,
seed=12345,
)
test_rand = generator.generate_dataframe(n_data * 10)
test_rand.rename(columns=dict(redshifts="z"), inplace=True)
handle_test_rand = Hdf5Handle("input_rand", test_rand)
2. Splitting and caching the data
This step is crucial to compute consistent clustering redshift uncertainties. yet_another_wizz uses spatial (jackknife) resampling and therefore, every input dataset must be split into the same exact spatial regions/patches. To improve the parallel performance, the datasets and randoms are pre-arranged into these patches and cached on disk for better random patch-wise access. While this is slow for small datasets, it is highly beneficial for large datasets with many patches and/or memory constraints.
The RAIL wrapper uses manually specified cache directories, each of
which contains one dataset and optionally corresponding randoms. This
ensures that the patch centers are defined consistently. To create a new
cache, use the YawCacheCreate.create() method.
Note on names and aliasing in RAIL
We need to create separate caches for the reference and the unknown
data, which means that we need to run the YawCacheCreate twice.
Since that creates name clashes in the RAIL datastore, we need to
properly alias the inputs (data/ rand) and the output
(cache) by providing a dictionary for the aliases parameter when
calling the make_stage(), e.g. by adding a unique suffix:
name = "stage_name"
aliases = dict(data="data_suffix", rand="rand_suffix", cache="cache_suffix")
There is a shorthand for convenience
(from rail.yaw_rail.cache.AliasHelper) that allows to generate this
dictionary by just providing a suffix name for the stage instance (see
example below).
name = "stage_name"
aliases = create_yaw_cache_alias("suffix")
The reference data
To create a cache directory we must specify a path to the directory
at which the data will be cached. This directory must not exist yet. We
also have to specify a name for the stage to ensure that the
reference and unknown caches (see below) are properly aliased to be
distinguishable by the RAIL datastore.
Furthermore, a few basic column names that describe the tabular input
data must be provided. These are right ascension (ra_name) and
declination (dec_name), and in case of the reference sample also the
redshifts (redshift_name). Finally, the patches must be defined and
there are three ways to do so: 1. Stage parameter patch_file: Read
the patch center coordinates from an ASCII file with pairs of
R.A/Dec. coordinates in radian. 2. Stage parameter patch_num:
Generating a given number of patches from the object positions
(peferrably of the randoms if possible) using k-means clustering. 3.
Stage parameter patch_name: Providing a column name in the input
table which contains patch indices (using 0-based indexing). 4. Stage
input patch_source: Using the patch centers from a different cache
instance, given by a cache handle. When this input is provided it takes
precedence over any of the stage parameters above.
In this example we choose to auto-generate five patches. In a more realistic setup this number should be much larger.
stage_cache_ref = ri.estimation.algos.cc_yaw.yaw_cache_create(
data=handle_test_data,
path=CACHE_DIR / "ref",
rand=handle_test_rand,
aliases=create_yaw_cache_alias("ref"),
overwrite=True, # default: False
ra_name="ra",
dec_name="dec",
redshift_name="z",
patch_source="none",
# weight_name=None,
# patch_name=None,
patch_num=5, # default: None
# max_workers=None,
verbose=VERBOSE, # default: "info"
)
Inserting handle into data store. data_ref: <class 'rail.core.data.Hdf5Handle'> None, (d), YawCacheCreate
Inserting handle into data store. rand_ref: <class 'rail.core.data.Hdf5Handle'> None, (d), YawCacheCreate
Inserting handle into data store. patch_source_ref: none, YawCacheCreate
YAW | yet_another_wizz v3.1.2
INF | running in multiprocessing environment with 2 workers
INF | loading 1M records in 1 chunks from memory
DBG | selecting input columns: ra, dec, z
DBG | creating 5 patches
INF | computing 5 patch centers from subset of 224K records
DBG | running preprocessing on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | using cache directory: ../examples_data/yaw_cache/ref/rand
INF | computing patch metadata
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | loading 100K records in 1 chunks from memory
DBG | selecting input columns: ra, dec, z
DBG | applying 5 patches
DBG | running preprocessing on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | using cache directory: ../examples_data/yaw_cache/ref/data
INF | computing patch metadata
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
Inserting handle into data store. output_ref: inprogress_output_ref.path, YawCacheCreate
We can see from the log messages that yet_another_wizz processes the
randoms first and generates patch centers (creating 5 patches) and
then applies them to the dataset, which is processed last
(applying 5 patches). Caching the data can take considerable time
depending on the hardware and the number of patches.
The unknown data
The same procedure for the unknown sample, however there are some small,
but important differences. We use a different path and name, do
not specify the redshift_name (since we would not have this
information with real data), and here we chose to not provide any
randoms for the unknown sample and instead rely on the reference sample
randoms for cross-correlation measurements.
Most importantly, we must ensure that the patch centers are consistent
with the reference data and therefore provide the reference sample cache
as a stage input called patch_source.
Important: Even if the reference and unknown data are the same as in
this specific case, the automatically generated patch centers are not
deterministic. We can see in the log messages that the code reports
applying 5 patches.
handle_cache_unk = ri.estimation.algos.cc_yaw.yaw_cache_create(
data=handle_test_data,
path=CACHE_DIR / "unk",
rand="none",
patch_source=stage_cache_ref["output"],
name="cache_unk",
aliases=create_yaw_cache_alias("unk"),
overwrite=True, # default: False
ra_name="ra",
dec_name="dec",
# redshift_name=None,
# weight_name=None,
# patch_name=None,
# patch_num=None,
# max_workers=None,
verbose=VERBOSE, # default: "info"
)["output"]
Inserting handle into data store. data_unk: <class 'rail.core.data.Hdf5Handle'> None, (d), cache_unk
Inserting handle into data store. rand_unk: none, cache_unk
Inserting handle into data store. patch_source_unk: YawCache(path='../examples_data/yaw_cache/ref'), cache_unk
YAW | yet_another_wizz v3.1.2
INF | running in multiprocessing environment with 2 workers
INF | loading 100K records in 1 chunks from memory
DBG | selecting input columns: ra, dec
DBG | applying 5 patches
DBG | running preprocessing on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | using cache directory: ../examples_data/yaw_cache/unk/data
INF | computing patch metadata
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
Inserting handle into data store. output_cache_unk: inprogress_output_cache_unk.path, cache_unk
3. Computing the autocorrelation / bias correction
The bias correction is computed from the amplitude of the angular autocorrelation function of the reference sample. The measurement parameters are the same as for the cross-correlation amplitude measurement, so we can define all configuration parameters once in a dictionary.
As a first step, we need to decide on which redshift bins/sampling we
want to compute the clustering redshifts. Here we choose the redshift
limits of the reference data (zmin/zmax) and, since the sample
is small, only 8 bins (zbin_num) spaced linearly in redshift
(default method="linear"). Finally, we have to define the physical
scales in kpc (rmin/rmax, converted to angular separation at
each redshift) on which we measure the correlation amplitudes.
Optional parameters: Bins edges can alternatively specifed manually
through zbins. To apply scale dependent weights,
e.g. \(w \propto r^{-1}\), specify the power-law exponent
asrweight=-1. The parameter resolution specifies the radial
resolution (logarithmic) of the weights.
corr_config = dict(
rmin=100, # in kpc
rmax=1000, # in kpc
# rweight=None,
# resolution=50,
zmin=zmin,
zmax=zmax,
num_bins=8, # default: 30
# method="linear",
# edges=np.linspace(zmin, zmax, zbin_num+1)
# closed="right",
# max_workers=None,
verbose=VERBOSE, # default: "info"
)
We then measure the autocorrelation using the
YawAutoCorrelate.correlate() method, which takes a single parameter,
the cache (handle) of the reference dataset.
result_auto_corr = ri.estimation.algos.cc_yaw.yaw_auto_correlate(
sample=stage_cache_ref["output"], **corr_config
)
Inserting handle into data store. sample: YawCache(path='../examples_data/yaw_cache/ref'), YawAutoCorrelate
YAW | yet_another_wizz v3.1.2
INF | running in multiprocessing environment with 2 workers
INF | building data trees
DBG | building patch-wise trees (using 8 bins)
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | building random trees
DBG | building patch-wise trees (using 8 bins)
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | computing auto-correlation from DD, DR, RR
DBG | computing patch linkage with max. separation of 1.42e-03 rad
DBG | created patch linkage with 19 patch pairs
DBG | using 1 scales without weighting
INF | counting DD from patch pairs
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | counting DR from patch pairs
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | counting RR from patch pairs
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
Inserting handle into data store. output: inprogress_output.hdf5, YawAutoCorrelate
As the code is progressing, we can observe the log messages of yet_another_wizz which indicate the performed steps: getting the cached data, generating the job list of patches to correlate, and counting pairs. Finally, the pair counts are stored as custom data handle in the datastore.
We can interact with the returned pair counts (yaw.CorrFunc,
documentation)
manually if we want to investigate the results:
counts_auto = result_auto_corr["output"] # extract payload from handle
counts_auto.dd
NormalisedCounts(auto=True, binning=8 bins @ (0.200...1.800], num_patches=5)
4. Computing the cross-correlation / redshift estimate
The cross-correlation amplitude, which is the biased estimate of the
unknown redshift distribution, is computed similarly to the
autocorrelation above. We measure the correlation using the
YawCrossCorrelate.correlate() method, which takes two parameters,
the cache (handles) of the reference and the unknown data.
result_cross_corr = ri.estimation.algos.cc_yaw.yaw_cross_correlate(
reference=stage_cache_ref["output"], unknown=handle_cache_unk, **corr_config
)
Inserting handle into data store. reference: YawCache(path='../examples_data/yaw_cache/ref'), YawCrossCorrelate
Inserting handle into data store. unknown: YawCache(path='../examples_data/yaw_cache/unk'), YawCrossCorrelate
YAW | yet_another_wizz v3.1.2
INF | running in multiprocessing environment with 2 workers
INF | building reference data trees
DBG | building patch-wise trees (using 8 bins)
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | building reference random trees
DBG | building patch-wise trees (using 8 bins)
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | building unknown data trees
DBG | building patch-wise trees (unbinned)
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | computing cross-correlation from DD, RD
DBG | computing patch linkage with max. separation of 1.42e-03 rad
DBG | created patch linkage with 19 patch pairs
DBG | using 1 scales without weighting
INF | counting DD from patch pairs
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
INF | counting RD from patch pairs
DBG | running parallel jobs on 2 workers
WRN | os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock.
Inserting handle into data store. output: inprogress_output.hdf5, YawCrossCorrelate
As before, we can see the actions performed by yet_another_wizz. The main difference for the cross-correlation function is that the second sample (the unknown data/randoms) are not binned by redshift when counting pairs.
As for the autocorrelation, we can interact with the result, e.g. by evaluating the correlation estimator manually and getting the cross-correlation amplitude per redshift bin.
counts_cross = result_cross_corr["output"] # extract payload from handle
corrfunc = counts_cross.sample() # evaluate the correlation estimator
corrfunc.data
DBG | sampling correlation function with estimator 'DP'
array([0.0023559 , 0.00403239, 0.00684468, 0.01126758, 0.00945143,
0.00898257, 0.00882812, 0.01273689])
5. Computing the redshift estimate
The final analysis step is combining the two measured correlation amplitudes to get a redshift estimate which is corrected for the reference sample bias. This estimate is not a PDF. Converting the result to a proper PDF (without negative values) is non-trivial and requires further modelling stages that are currently not part of this wrapper.
We use YawSummarize.summarize() method, which takes the pair count
handles of the cross- and autocorrelation functions as input. In
principle, the autocorrelation of the unknown sample could be specified
to fully correct for galaxy bias, however this is not possible in
practice since the exact redshifts of the unknown objects are not known.
result_summarize = ri.estimation.algos.cc_yaw.yaw_summarize(
cross_corr=result_cross_corr["output"],
auto_corr_ref=result_auto_corr["output"], # default: None
auto_corr_unk="none",
verbose=VERBOSE, # default: "info"
)
Inserting handle into data store. cross_corr: CorrFunc(counts=dd|rd, auto=False, binning=8 bins @ (0.200...1.800], num_patches=5), YawSummarize
Inserting handle into data store. auto_corr_ref: CorrFunc(counts=dd|dr|rr, auto=True, binning=8 bins @ (0.200...1.800], num_patches=5), YawSummarize
Inserting handle into data store. auto_corr_unk: none, YawSummarize
YAW | yet_another_wizz v3.1.2
INF | running in multiprocessing environment with 2 workers
DBG | sampling correlation function with estimator 'DP'
DBG | sampling correlation function with estimator 'LS'
DBG | computing clustering redshifts from correlation function samples
DBG | mitigating reference sample bias
Inserting handle into data store. output: inprogress_output.pkl, YawSummarize
The stage produces a single output which contains the redshift estimate
with uncertainties, jackknife samples of the estimate, and a covariance
matrix. These data products are wrapped as yaw.RedshiftData
documentation
which gets stored as pickle file when running a ceci pipeline.
Some examples on how to use this data is shown below.
Remove caches
The cached datasets are not automatically removed, since the algorithm does not know when they are no longer needed. Additionally, the reference data could be resued for future runs, e.g. for different tomographic bins.
Since that is not the case here, we just delete the cached data with a built-in method.
stage_cache_ref["output"].data.drop()
handle_cache_unk.data.drop()
Inspect results
Below are some examples on how to access the redshift binning, estimate, estimte error, samples and covariance matrix produced by yet_another_wizz.
ncc = result_summarize["output"]
ncc.data / ncc.error # n redshift slices
array([0.99751831, 2.37893624, 2.14804959, 7.20831464, 2.18093417,
5.07480432, 2.19060571, 2.21372888])
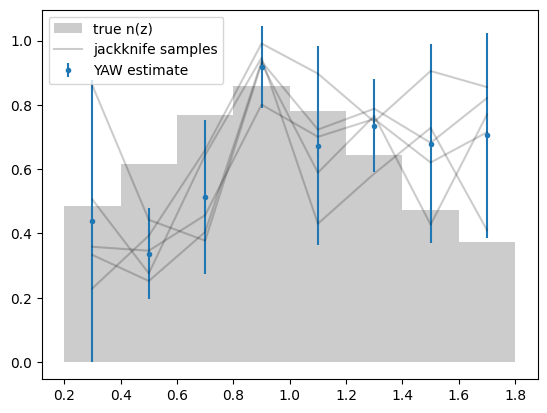
# true n(z)
zbins = result_cross_corr["output"].binning.edges
plt.hist(test_data["z"], zbins, density=True, color="0.8", label="true n(z)")
# fiducial n(z)
normalised = ncc.normalised() # copy of data with n(z) is normalised to unity
ax = normalised.plot(label="YAW estimate")
# jackknife samples
normalised.samples.shape # m jackknife-samples x n redshift slices
z = normalised.binning.mids
plt.plot(z, normalised.samples.T, color="k", alpha=0.2)
# create a dummy for the legend
plt.plot([], [], color="k", alpha=0.2, label="jackknife samples")
ax.legend()
DBG | normalising RedshiftData
<matplotlib.legend.Legend at 0x7ff2ae8479d0>
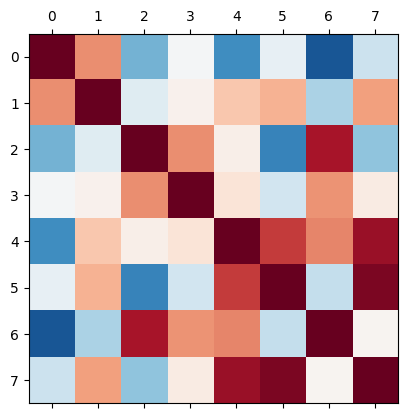
ncc.covariance.shape # n x n redshift slices
ncc.plot_corr()
<Axes: >
Clean up Files
shutil.rmtree(CACHE_DIR)